The
Impact of RSS on Information Overload
As my periodic Newzcrawler news feeds
flashed before me (every two hours), an item titled “RSS Killed The Infoglut Star” caught
my attention. So I commenced to skim through the article, and was struck by the
following commentary from the TechDirt (one of
many RSS based channels):
“Here is yet another article raving about how RSS changes how
they get information. I've heard this same
story so many times that I'm a bit confused. I keep trying the various RSS
readers, and I just haven't been hooked. I use them for a few days, and then
realize that my old method of surfing websites was much more enjoyable and much
more efficient”.
The great thing
about this article is the nature of the question posed, it is inherently
multi-faceted (this may or may not have been the original intent), and I hope
to shed light (at least hopefully) on these facets via this post. Here are the
facets that I have discerned from this questions (there might be more) which I
enumerate as follows:
- Are New Aggregators providing a
better experience than conventional Web Browsing?
[Yes in my opinion]
- Even when the total costs vs.
benefits of either approach are analyzed?
[Not at the current time, but blogosphere time lag is nothing like what many are used to, the problem will be solved in a matter of weeks (if not sooner) ]
The Case For News Aggregators hosted Browsing over Conventional Browsing
Chad
Dickerson’s original article pretty much
sums it up, and here is a key excerpt:
“Over the past few years, the Web itself has become like a
blabbering acquaintance with a million fleeting and unconnected ideas, and
e-mail has become a crowded cocktail party with a few interesting people whose
words are obscured by the gaggle of others frantically trying to sell various
unmentionables. With more and more traditional media companies supporting RSS
every day and the unmediated voices of thought leaders such as Ray Ozzie and Tim Bray coming through my newsreader via
RSS-enabled Weblogs, using my newsreader is like having a cocktail party for
busy people where the conversation is lively and almost always to the
point.”
Information
overload is the main problem that News Aggregators alleviate. They enable
selective viewing of relevant web content, and this saves time. Even more
profound is the fact that the viewing is increasingly contextual; one relevant
article leads you to another (See the sharp reader screenshot below).
To show how this
process plays out -which I believe unveils what the excitement and challenges
are all about- I have enumerated a sequence of events below that journal the
actions I took after reading the initial TecDirt RSS feed.
1. Switched to
from Newzcrawler to SharpReader to see if
there was additional commentary in my blogosphere (my
collection of subscriptions to blogs and other
RSS formatted data sources). Newscrawlers inability
to connect these posts automatically is what lead to my need to kick off a
SharpReader instance
2. Imported Chad Dickerson’s and TechDirt’s RSS feeds.
A quicker approach would be to import an OPML file which
Newzcrawler does produce, but
3. Attempted to
use SharpReader’s “BlogThis plugin” to
write this blog entry.
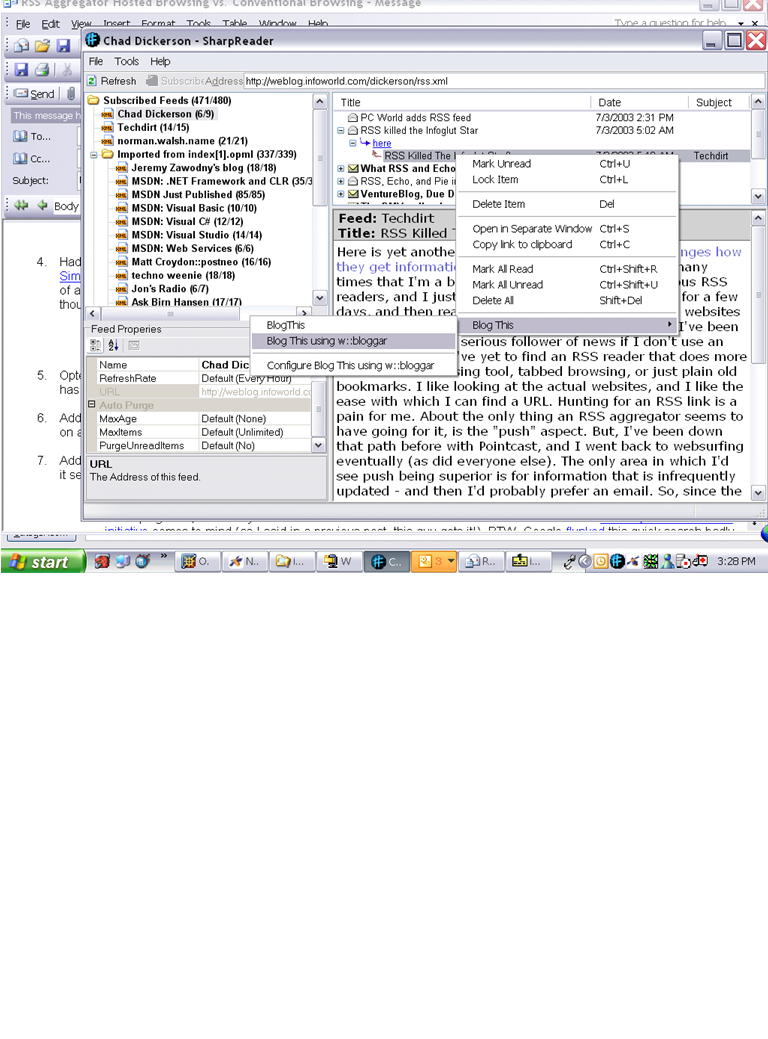
4. Had to
abort! This has nothing to do with SharpReader as it’s
use of the IBlogThis and IBlogThis extensions
(courtesy of Simon Fell) are
exemplary. I realized this post was going to get lengthy and I wanted to use a
tool that better served the task of article writing. Thus, I need complete this
effort using a Word processor (kicking off Microsoft Word was my initial
though)
a. Quandary!
Word has no blogging capability (a glaring omission that I presume the folks at
Microsoft, or an ingenious third party, will resolve pretty soon)
5. Opted to
look into OutLook (It also just occurred to me that this might be a good time
to look at the NewsGator plugin) which has transparent
integration with Word.
6. Added Chad
Dickerson’s RSS feed to my NewsGator subscription lists (his article
earned my subscription to his RSS Feeds on a permanent basis, so I added his feed
to my Blog Roll)
7. Added
Techdirt’s RSS feed to my
channel roll (it was already part of my Newscrawler subscriptions list, but
this post earned it separation from my mass of channel feeds, so I added
TechDirt to my permanent Channel Roll)
a. Subscribed
to the same RSS feeds using NewsGator (again! I just did this with
SharpReader). There is a pattern developing here, how many times do I have to
subscribe to the same feeds? Dave Winer’s subscription Harmonizer initiative comes to
mind (as I said in a previous post, this guy gets it!). BTW. Google flunked this quick search
badly, so I tried Feedster, and received better results (I hope
this Google and Blog conundrum hasn’t put Google in a tizzy!)
b. Back to
Newzcrawler to blast a context search over my feeds an viola (the I get the
exact page which I then used for the subscription harmonizer
url above)
8. Attempted a Trackback or Pingback to both
Chad and TechDirt so that both of the article writers would be aware of my
referencing their pieces, but unfortunately neither site had this blog feature
in place (or enabled), same applied to a comments facility on either site
9. Article is
completed, it is clearly too long to be a blog post in its own right, so I have
to save this as an article/story on my blog site. Hmm. Luckily I am using Virtuoso which
supports HTTP and WebDAV to host my Blog Sites -company hosted, personal, and community (It’s
wonderful experience using your own technology to do practical things like
demonstrating it’s many uses)
a. I create a
Windows Web Folder (could have
done the same on Mac OS X or Linux if these were my main working machines; they
certainly aren’t that far away from forcing my hand)
b. I point the
Windows folder to my blog’s home
directory
c. Create a new
“articles” and “images” sub-folders
under my blog’s home directory
d. Perform a File|Save As from OutLook (telling it I want to save this
article as a Web Page; note this is OutLook 2003 although the same should be
achievable using 2000)
e. Copy the
larger version of my “SharpReader” image to the “images”
folder and then anchor to this from the smaller image in my article (an option
for those who want to see an enlarged view of SharpReader connecting
The Cost-Benefit Analysis
of News Aggregators hosted Browsing vs. Conventional Browsing
It was quite a
journey (3.5 hours to be precise) getting this article (or post) completed in
line with my initial goals (demonstrating why News Aggregators hosted Browsing
is better than Conventional Browsing). This might be the route taken by the
TechDirt article author, hence the resulting position (not quite there yet).
That being the case it’s certainly possible to see how the current costs
may exceed perceived immediate benefits.
From a personal
perspective this was one the more intriguing blog posts that I have written to
date, I spent 3.5 hours on this but, it was absolutely worth it for the
following reasons:
- Placing the Weblog phenomenon in
relevant context; the article and the deliberately placed links help to
demystify blogging
- Making this article accessible
from my blog assists with the dissemination of information and knowledge
embedded with this article
- The pros and cons of a number
of blogosphere tools (News Reader, Content Aggregators, Plugins, Blog Posting Clients and Programming Interfaces
etc.) have been unveiled, and I expect most of the issues raised to
accelerate product enhancements or spur new product entrants into this
most exhilarating space (it’s a win-win situation)
- Contextual testing of Virtuoso’s
in-built XML Services (Validating
XML Parser, XSL-T processor, and SQL-XML), WebDAV,
and Weblog Posting API (Blogger, MoveableType, and MetaWeblog) implementations
- Continues to validate where my
view that the Semantic Web will
work as it is rapidly assembling itself at a frenetic pace