In this post I provide a brief re-introduction to this essential aspect of Virtuoso.
This component of Virtuoso is known as the Virtual Database Engine (VDBMS). It provides transparent high-performance and secure access to disparate data sources that are external to Virtuoso. It enables federated access and integration of data hosted by any ODBC- or JDBC-accessible RDBMS, RDF Store, XML database, or Document (Free Text)-oriented Content Management System. In addition, it facilitates integration with Web Services (SOAP-based SOA RPCs or REST-fully accessible Web Resources).
In the most basic sense, you shouldn't need to upgrade your existing database engine version simply because your current DBMS and Data Access Driver combo isn't compatible with ODBC-compliant desktop tools such as Microsoft Access, Crystal Reports, BusinessObjects, Impromptu, or other of ODBC, JDBC, ADO.NET, or OLE DB-compliant applications. Simply place Virtuoso in front of your so-called "legacy database," and let it deliver the compliance levels sought by these tools
In addition, it's important to note that today's enterprise, through application evolution, company mergers, or acquisitions, is often faced with disparately-structured data residing in any number of line-of-business-oriented data silos. Compounding the problem is the exponential growth of user-generated data via new social media-oriented collaboration tools and platforms. For companies to cost-effectively harness the opportunities accorded by the increasing intersection between line-of-business applications and social media, virtualization of data silos must be achieved, and this virtualization must be delivered in a manner that doesn't prohibitively compromise performance or completely undermine security at either the enterprise or personal level. Again, this is what you get by simply installing Virtuoso.
The VDBMS may be used in a variety of ways, depending on the data access and integration task at hand. Examples include:
You can make a single ODBC, JDBC, ADO.NET, OLE DB, or XMLA connection to multiple ODBC- or JDBC-accessible RDBMS data sources, concurrently, with the ability to perform intelligent distributed joins against externally-hosted database tables. For instance, you can join internal human resources data against internal sales and external stock market data, even when the HR team uses Oracle, the Sales team uses Informix, and the Stock Market figures come from Ingres!
You can construct RDF Model-based Conceptual Views atop Relational Data Sources. This is about generating HTTP-based Entity-Attribute-Value (E-A-V) graphs using data culled "on the fly" from native or external data sources (Relational Tables/Views, XML-based Web Services, or User Defined Types).
You can also derive RDF Model-based Conceptual Views from Web Resource transformations "on the fly" -- the Virtuoso Sponger (RDFizing middleware component) enables you to generate RDF Model Linked Data via a RESTful Web Service or within the process pipeline of the SPARQL query engine (i.e., you simply use the URL of a Web Resource in the FROM clause of a SPARQL query).
It's important to note that Views take the form of HTTP links that serve as both Data Source Names and Data Source Addresses. This enables you to query and explore relationships across entities (i.e., People, Places, and other Real World Things) via HTTP clients (e.g., Web Browsers) or directly via SPARQL Query Language constructs transmitted over HTTP.
As an alternative to RDF, Virtuoso can expose ADO.NET Entity Frameworks-based Conceptual Views over Relational Data Sources. It achieves this by generating Entity Relationship graphs via its native ADO.NET Provider, exposing all externally attached ODBC- and JDBC-accessible data sources. In addition, the ADO.NET Provider supports direct access to Virtuoso's native RDF database engine, eliminating the need for resource intensive Entity Frameworks model transformations.
Of course, I also believe that Linked Data serves Web Data Integration across the Internet very well too, and the fact that it will be beneficial to businesses in a big way. No individual or organization is an island, I think the Internet and Web have done a good job of demonstrating that thus far :-) We're all data nodes in a Giant Global Graph.
Daniel lewis did shed light on the read-write aspects of the Linked Data Web, which is actually very close to the callout for a Wikipedia for Data. TimBL has been working on this via Tabulator (see Tabulator Editing Screencast), Bengamin Nowack also added similar functionality to ARC, and of course we support the same SPARQL UPDATE into an RDF information resource via the RDF Sink feature of our WebDAV and ODS-Briefcase implementations.
]]>The list is nice, but actual execution can be challenging. For instance, when writing a blog post, or constructing a WikiWord, would you have enough disposable time to go searching for these URIs? Or would you compromise and continue to inject "Literal" values into the Web, leaving it to the reasoning endowed human reader to connect the dots?
Anyway, OpenLink Data Spaces is now equipped with a Glossary system that allows me to manage terms, meaning of terms, and hyper-linking of phrases and words matching associated with my terms. The great thing about all of this is that everything I do is scoped to my Data Space (my universe of discourse), I don't break or impede the other meanings of these terms outside my Data Space. The Glossary system can be shared with anyone I choose to share it with, and even better, it makes my upstreaming (rules based replication) style of blogging even more productive :-)
Remember, on the Linked Data Web, who you know doesn't matter as much as what your are connected to, directly or indirectly. Jason Kolb covers this issue in his post: People as Data Connectors, and so doesFrederick Giasson via a recent post titled: Networks are everywhere. For instance, this blog post (or the entire Blog) is a bona fide RDF Linked Data Source, you can use it as the Data Source of a SPARQL Query to find things that aren't even mentioned in this post, since all you are doing is beaming a query through my Data Space (a container of Linked Data Graphs). On that note, let's re-watch Jon Udell's "On-Demand-Blogosphere" screencast from 2006 :-)
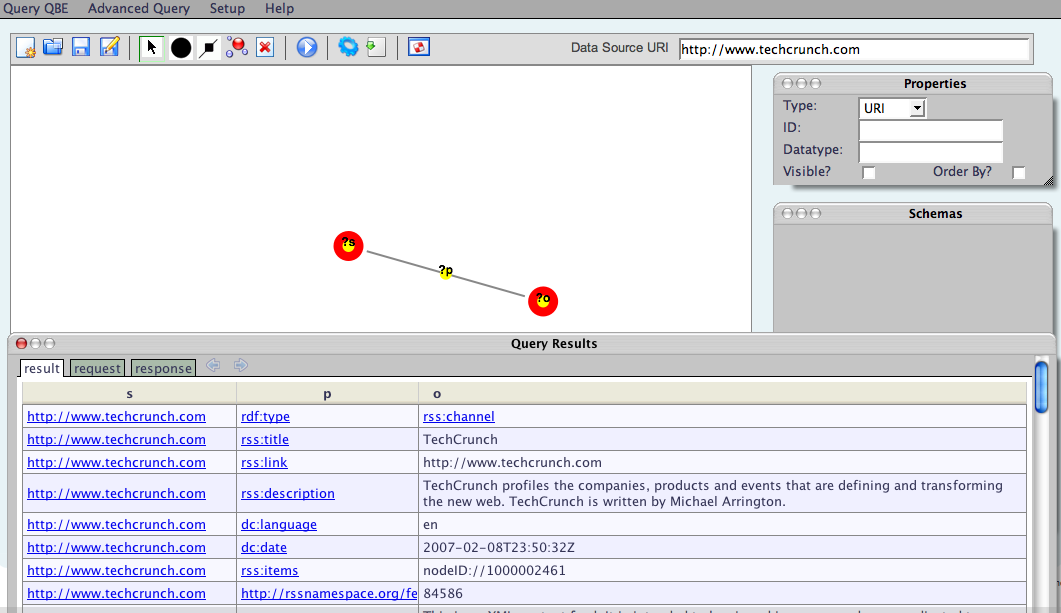
]]>Once you grasp the concept of entering values into the "Default Data Source URI field", take a look at: http://programmableweb.com and other URIs (hint: scroll through the results grid to the QEDWiki demo item)
]]>What I am demonstrating is how existing Web Content hooks transperently into the "Data Web". Zero RDF Tax :-) Everything is good!
Note: Please look to the bottom of the screen for the "Run Query" Button. Remember, it not quite Grandma's UI but should do for Infonauts etc.. A screencast will follow.
]]>SPARQL (query language for the Semantic Web) basically enables me to query a collection of typed links (predicates/properties/attributes) in my Data Space (ODS based of course) without breaking my existing local bookmarks database or the one I maintain at del.icio.us.
I am also demonstrating how Web 2.0 concepts such as Tagging mesh nicely with the more formal concepts of Topics in the Semantic Web realm. The key to all of this is the ability to generate RDF Data Model Instance Data based on Shared Ontologies such as SIOC (from DERI's SIOC Project) and SKOS (again showing that Ontologies and Folksonomies are complimentary).
This demo also shows that Ajax also works well in the Semantic Web realm (or web dimension of interaction 3.0) especially when you have a toolkit with Data Aware controls (for SQL, RDF, and XML) such as OAT (OpenLink Ajax Toolkit). For instance, we've successfully used this to build a Visual Query Building Tool for SPARQL (alpha) that really takes a lot of the pain out of constructing SPARQL Queries (there is much more to come on this front re. handling of DISTINCT, FILTER, ORDER BY etc..).
For now, take a look at the SPARQL Query dump generated by this SIOC & SKOS SPARQL QBE Canvas Screenshot.
You can cut and paste the queries that follow into the Query Builder or use the screenshot to build your variation of this query sample. Alternatively, you can simply click on *This* SPARQL Protocol URL to see the query results in a basic HTML Table. And one last thing, you can grab the SPARQL Query File saved into my ODS-Briefcase (the WebDAV repository aspect of my Data Space).
Note the following SPARQL Protocol Endpoints:
My beautified Version of the SPARQL Generated by QBE (you can cut and paste into "Advanced Query" section of QBE) is presented below:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX sioc: <http://rdfs.org/sioc/ns#> PREFIX dct: <http://purl.org/dc/elements/1.1/> PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
SELECT distinct ?forum_name, ?owner, ?post, ?title, ?link, ?url, ?tag FROM <http://myopenlink.net/dataspace> WHERE { ?forum a sioc:Forum; sioc:type "bookmark"; sioc:id ?forum_name; sioc:has_member ?owner. ?owner sioc:id "kidehen". ?forum sioc:container_of ?post . ?post dct:title ?title . optional { ?post sioc:link ?link } optional { ?post sioc:links_to ?url } optional { ?post sioc:topic ?topic. ?topic a skos:Concept; skos:prefLabel ?tag}. }
Unmodified dump from the QBE (this will be beautified automatically in due course by the QBE):
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX sioc: <http://rdfs.org/sioc/ns#> PREFIX dct: <http://purl.org/dc/elements/1.1/> PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
SELECT ?var8 ?var9 ?var13 ?var14 ?var24 ?var27 ?var29 ?var54 ?var56 WHERE { graph ?graph { ?var8 rdf:type sioc:Forum . ?var8 sioc:container_of ?var9 . ?var8 sioc:type "bookmark" . ?var8 sioc:id ?var54 . ?var8 sioc:has_member ?var56 . ?var9 rdf:type sioc:Post . OPTIONAL {?var9 dc:title ?var13} . OPTIONAL {?var9 sioc:links_to ?var14} . OPTIONAL {?var9 sioc:link ?var29} . ?var9 sioc:has_creator ?var37 . OPTIONAL {?var9 sioc:topic ?var24} . ?var24 rdf:type skos:Concept . OPTIONAL {?var24 skos:prefLabel ?var27} . ?var56 rdf:type sioc:User . ?var56 sioc:id "kidehen" . } }
Current missing items re. Visual QBE for SPARQL are:
Quick Query Builder Tip: You will need to import the following (using the Import Button in the Ontologies & Schemas side-bar);
Browser Support: The SPARQL QBE is SVG based and currently works fine with the following browsers; Firefox 1.5/2.0, Camino (Cocoa variant of Firefox for Mac OS X), Webkit (Safari pre-release / advanced sibling), Opera 9.x. We are evaluating the use of the Adobe SVG plugin re. IE 6/7 support.
Of course this should be a screencast, but I am the middle of a plethora of things right now :-)
]]>The screencasts covered the following functionality realms:
To bring additional clarity to the screencasts demos and OAT in general, I have saved a number of documents that are the by products of activities in the screenvcasts:
Notes:
You can see a full collection of saved documents at the following locations:
A powerful next generation server product that implements otherwise distinct server functionality within a single server product. Think of Virtuoso as the server software analog of a dual core processor where each core represents a traditional server functionality realm.
The Virtuoso History page tells the whole story.
90% of the aforementioned functionality has been available in Virtuoso since 2000 with the RDF Triple Store being the only 2006 item.
The Virtuoso build scripts have been successfully tested on Mac OS X (Universal Binary Target), Linux, FreeBSD, and Solaris (AIX, HP-UX, and True64 UNIX will follow soon). A Windows Visual Studio project file is also in the works (ETA some time this week).
Simple, there is no value in a product of this magnitude remaining the "best kept secret". That status works well for our competitors, but absolutely works against the legions of new generation developers, systems integrators, and knowledge workers that need to be aware of what is actually achievable today with the right server architecture.
GPL version 2.
Dual licensing.
The Open Source version of Virtuoso includes all of the functionality listed above. While the Virtual Database (distributed heterogeneous join engine) and Replication Engine (across heterogeneous data sources) functionality will only be available in the commercial version.
On SourceForge.
Of course!
Up until this point, the Virtuoso Product Blog has been a covert live demonstration of some aspects of Virtuoso (Content Management). My Personal Blog and the Virtuoso Product Blog are actual Virtuoso instances, and have been so since I started blogging in 2003.
Is There a product Wiki?
Sure! The Virtuoso Product Wiki is also an instance of Virtuoso demonstrating another aspect of the Content Management prowess of Virtuoso.
Yep! Virtuoso Online Documentation is hosted via yet another Virtuoso instance. This particular instance also attempts to demonstrate Free Text search combined with the ability to repurpose well formed content in a myriad of forms (Atom, RSS, RDF, OPML, and OCS).
The Virtuoso Online Tutorial Site has operated as a live demonstration and tutorial portal for a numbers of years. During the same timeframe (circa. 2001) we also assembled a few Screencast style demos (their look feel certainly show their age; updates are in the works).
BTW - We have also updated the Virtuoso FAQ and also released a number of missing Virtuoso White Papers (amongst many long overdue action items).
]]>Stop whatever you are doing ...: "
(Spotted Via The Obvious?.)
Yes, the ramifications are deep! Tom Coates' screencast demonstrates an internal variation of an activity that is taking place on many fronts (concurrently) across the NET. I tend to refer to this effort as "Self Annotation"; the very process that will ultimately take us straight to "Semantic Web". It is going to happen much quicker than anticipated because technology is taking the pain out of metadata annotation (e.g. what you do when you tag everything that is ultimately URI accessible). Technology is basically delivering what Jon Udell calls: "reducing the activation threshold".
Using my comments above for context placement, I suggest you take a look at, or re-read Jon Udell's post titled: Many Meanings of Metadata.
Once again, the Web 2.0 brouhaha (in every sense of the word) is a reaction to a critical inflection that ultimately transitions the "Semantic Web" from "Mirage" to "Nirvana". Put differently (with humor in mind solely!), Web 2.0 is what I tend to call a "John the Baptist" paradigm, and we all know what happened to him :-)
Web 2.0 is a conduit to a far more important destination. The tendency to treat Web 2.0 as a destination rather than a conduit has contributed to the recent spate of Bozo bit flipping posts all over the blogosphere (is this an attempt to behead John, metaphorically speaking?). Humor aside, a really important thing about the Web 2.0 situation is that when we make the quantum evolutionary leap (internet time, mind you) to the "Semantic Web" (or whatever groovy name we dig up for it in due course) we will certainly have a plethora of reference points (I mean Web 2.0 URIs) ensuring that we do not revisit the "Missing Link" evolutionary paradox :-)
BTW - You can see some example of my contribution to the ongoing annotation process by looking at:
{kind=link}
{kind=link}
{kind=link}
{kind=link}