CrunchBase: When we released the CrunchBase API, you were one of the first developers to step up and quickly released a CrunchBase Sponger Cartridge. Can you explain what a CrunchBase Sponger Cartridge is?
Me: A Sponger Cartridge is a data access driver for Web Resources that plugs into our Virtuoso Universal Server (DBMS and Linked Data Web Server combo amongst other things). It uses the internal structure of a resource and/or a web service associated with a resource, to materialize an RDF based Linked Data graph that essentially describes the resource via its properties (Attributes & Relationships).
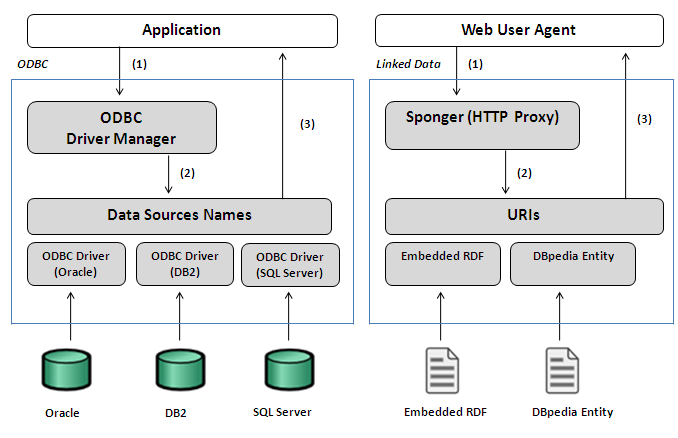
CrunchBase: And what inspired you to create it?
Me: Bengee built a new space with your data, and we've built a space on the fly from your data which still resides in your domain. Either solution extols the virtues of Linked Data i.e. the ability to explore relationships across data items with high degrees of serendipity (also colloquially known as: following-your-nose pattern in Semantic Web circles).
Bengee posted a notice to the Linking Open Data Community's public mailing list announcing his effort. Bearing in mind the fact that we've been using middleware to mesh the realms of Web 2.0 and the Linked Data Web for a while, it was a no-brainer to knock something up based on the conceptual similarities between Wikicompany and CrunchBase. In a sense, a quadrant of orthogonality is what immediately came to mind re. Wikicompany, CrunchBase, Bengee's RDFization efforts, and ours.
Bengee created an RDF based Linked Data warehouse based on the data exposed by your API, which is exposed via the Semantic CrunchBase data space. In our case we've taken the "RDFization on the fly" approach which produces a transient Linked Data View of the CrunchBase data exposed by your APIs. Our approach is in line with our world view: all resources on the Web are data sources, and the Linked Data Web is about incorporating HTTP into the naming scheme of these data sources so that the conventional URL based hyperlinking mechanism can be used to access a structured description of a resource, which is then transmitted using a range negotiable representation formats. In addition, based on the fact that we house and publish a lot of Linked Data on the Web (e.g. DBpedia, PingTheSemanticWeb, and others), we've also automatically meshed Crunchbase data with related data in DBpedia and Wikicompany data.
CrunchBase: Do you know of any apps that are using CrunchBase Cartridge to enhance their functionality?
Me: Yes, the OpenLink Data Explorer which provides CrunchBase site visitors with the option to explore the Linked Data in the CrunchBase data space. It also allows them to "Mesh" (rather than "Mash") CrunchBase data with other Linked Data sources on the Web without writing a single line of code.
CrunchBase: You have been immersed in the Semantic Web movement for a while now. How did you first get interested in the Semantic Web?
Me: We saw the Semantic Web as a vehicle for standardizing conceptual views of heterogeneous data sources via context lenses (URIs). In 1998 as part of our strategy to expand our business beyond the development and deployment of ODBC, JDBC, and OLE-DB data providers, we decided to build a Virtual Database Engine (see: Virtuoso History), and in doing so we sought a standards based mechanism for the conceptual output of the data virtualization effort. As of the time of the seminal unveiling of the Semantic Web in 1998 we were clear about two things, in relation to the effects of the Web and Internet data management infrastructure inflections: 1) Existing DBMS technology had reached it limits 2) Web Servers would ultimately hit their functional limits. These fundamental realities compelled us to develop Virtuoso with an eye to leveraging the Semantic Web as a vehicle from completing its technical roadmap.
CrunchBase: Can you put into laymanâs terms exactly what RDF and SPARQL are and why they are important? Do they only matter for developers or will they extend past developers at some point and be used by website visitors as well?
Me: RDF (Resource Description Framework) is a Graph based Data Model that facilitates resource description using the Subject, Predicate, and Object principle. Associated with the core data model, as part of the overall framework, are a number of markup languages for expressing your descriptions (just as you express presentation markup semantics in HTML or document structure semantics in XML) that include: RDFa (simple extension of HTML markup for embedding descriptions of things in a page), N3 (a human friendly markup for describing resources), RDF/XML (a machine friendly markup for describing resources).
SPARQL is the query language associated with the RDF Data Model, just as SQL is a query language associated with the Relational Database Model. Thus, when you have RDF based structured and linked data on the Web, you can query against Web using SPARQL just as you would against an Oracle/SQL Server/DB2/Informix/Ingres/MySQL/etc.. DBMS using SQL. That's it in a nutshell.
CrunchBase: On your website you wrote that âRDF and SPARQL as productivity boosters in everyday web developmentâ. Can you elaborate on why you believe that to be true?
Me: I think the ability to discern a formal description of anything via its discrete properties is of immense value re. productivity, especially when the capability in question results in a graph of Linked Data that isn't confined to a specific host operating system, database engine, application or service, programming language, or development framework. RDF Linked Data is about infrastructure for the true materialization of the "Information at Your Fingertips" vision of yore. Even though it's taken the emergence of RDF Linked Data to make the aforementioned vision tractable, the comprehension of the vision's intrinsic value have been clear for a very long time. Most organizations and/or individuals are quite familiar with the adage: Knowledge is Power, well there isn't any knowledge without accessible Information, and there isn't any accessible Information without accessible Data. The Web has always be grounded in accessibility to data (albeit via compound container documents called Web Pages).
Bottom line, RDF based Linked Data is about Open Data access by reference using URIs (HTTP based Entity IDs / Data Object IDs / Data Source Names), and as I said earlier, the intrinsic value is pretty obvious bearing in mind the costs associated with integrating disparate and heterogeneous data sources -- across intranets, extranets, and the Internet.
CrunchBase: In his definition of Web 3.0, Nova Spivack proposes that the Semantic Web, or Semantic Web technologies, will be force behind much of the innovation that will occur during Web 3.0. Do you agree with Nova Spivack? What role, if any, do you feel the Semantic Web will play in Web 3.0?
Me: I agree with Nova. But I see Web 3.0 as a phase within the Semantic Web innovation continuum. Web 3.0 exists because Web 2.0 exists. Both of these Web versions express usage and technology focus patterns. Web 2.0 is about the use of Open Source technologies to fashion Web Services that are ultimately used to drive proprietary Software as Service (SaaS) style solutions. Web 3.0 is about the use of "Smart Data Access" to fashion a new generation of Linked Data aware Web Services and solutions that exploit the federated nature of the Web to maximum effect; proprietary branding will simply be conveyed via quality of data (cleanliness, context fidelity, and comprehension of privacy) exposed by URIs.
Here are some examples of the CrunchBase Linked Data Space, as projected via our CruncBase Sponger Cartridge:
]]>