GPT-5 Knowledge Graph
An infographic-style view of entities, pricing, FAQs, and how-tos derived from a JSON-LD knowledge graph about GPT-5.
WebPage
CreativeWorkSeries
#series
Name: GPT-5
Organization
#publisher
Simon Willison's Weblog
OpenAI
sameAs: dbpedia.org/resource/OpenAI
Anthropic
sameAs: dbpedia.org/resource/Anthropic
Google AI
sameAs: dbpedia.org/resource/Google
xAI
AI company
Person
#simon-willison
Simon Willison — Engineer and writer covering AI, tools, and workflows.
Affiliation: Simon Willison's Weblog
BlogPosting
#article
- Headline: GPT-5: Key characteristics, pricing and model card
- Date: 2025-08-07T17:36:00
- Abstract: Hands-on notes covering GPT-5 models, routing, reasoning, limits, pricing, safety methods, thinking traces, prompt injection results, and fun pelican SVGs.
CreativeWork
#sec-key-model
GPT-5 offers unified routing, variants, reasoning levels, high token limits, and text-image input with text output.
#sec-model-family
GPT-5 variants replace much of OpenAI's lineup; Pro exists in ChatGPT with parallel test-time compute.
#sec-pricing
GPT-5 pricing undercuts rivals; token caching offers 90% discounts on repeated input tokens.
#sec-more-notes
Training sources remain vague; model improves writing, coding, and health with safe-completions.
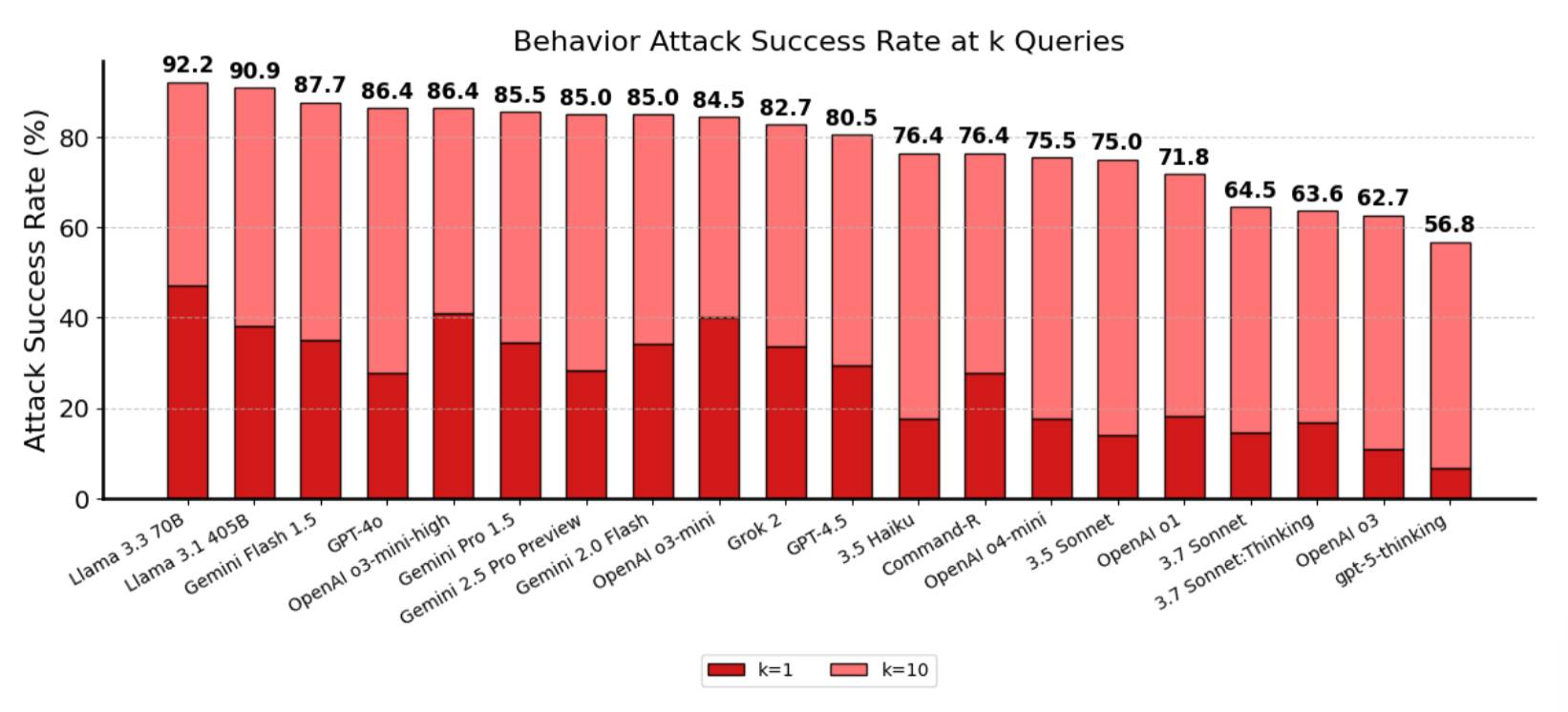
#sec-prompt-injection
Red teams saw improved resistance, yet attack success remained 56.8% for gpt-5-thinking.
#sec-thinking-traces
Reasoning summaries can be requested; minimal reasoning setting improves response latency.


VideoObject
ImageObject
Product
Offer
Each product includes two offers: input and output token pricing. Details in UnitPriceSpecification below.
See associated products above and UnitPriceSpecification for exact amounts and currencies.
UnitPriceSpecification
| Product | Type | Price (USD) | Unit |
|---|---|---|---|
| GPT-5 | Input | 1.25 | per million input tokens |
| GPT-5 | Output | 10.00 | per million output tokens |
| GPT-5 Mini | Input | 0.25 | per million input tokens |
| GPT-5 Mini | Output | 2.00 | per million output tokens |
| GPT-5 Nano | Input | 0.05 | per million input tokens |
| GPT-5 Nano | Output | 0.40 | per million output tokens |
| Claude Opus 4.1 | Input | 15.00 | per million input tokens |
| Claude Opus 4.1 | Output | 75.00 | per million output tokens |
| Claude Sonnet 4 | Input | 3.00 | per million input tokens |
| Claude Sonnet 4 | Output | 15.00 | per million output tokens |
| Grok 4 | Input | 3.00 | per million input tokens |
| Grok 4 | Output | 15.00 | per million output tokens |
| Gemini 2.5 Pro (>200k) | Input | 2.50 | per million input tokens |
| Gemini 2.5 Pro (>200k) | Output | 15.00 | per million output tokens |
FAQPage
Question
All FAQs above map to Question entities. Each has a linked Answer entity.
See the FAQ accordion for interactive browsing.
Answer
Answer entities are collapsed within the FAQ. Expand any question to view the answer text.
Answers include pricing, limits, modalities, safety, and reasoning details.
DefinedTermSet
#glossary
Key terms used throughout the article and FAQs.
DefinedTerm
safe-completions
Safety training emphasizing safe outputs over binary refusals.
sycophancy
Model tendency to agree with users; reduced in GPT-5 via post-training.
prompt injection
Attacks that manipulate model or tool behavior; still a risk.
reasoning tokens
Invisible tokens for internal reasoning; count toward output budget.
token caching
Reuse recent input tokens with large discounts.
parallel test-time compute
Compute strategy used in GPT-5 Pro to enhance throughput.
thinking traces
Summaries of internal reasoning via responses API.
router
Selects models based on complexity, tools, and user intent.
Mini
Smaller GPT-5 variant with lower cost.
Nano
Smallest GPT-5 variant focused on cost-efficiency.
usage limits
Quota thresholds triggering routing to mini models.
tool use
Model interaction with external tools; router considers needs.
browsing tool
Fetch web content for up-to-date info; default in ChatGPT.
reward signal
Score used in post-training (e.g., reduce sycophancy).
dual-use content
High-level guidance safe; detailed steps risk misuse.
How-Tos
Retrieve GPT-5 reasoning summaries via API
- Prepare request — Set model to 'gpt-5' and include reasoning summary='auto'.
- Send curl — Execute the curl command with your API key.
- Inspect response — Read the 'reasoning' summary field.
- Optimize latency — Set reasoning_effort='minimal'.
Implement token caching in a chat UI
- Identify cacheable segments — System prompt and prior messages.
- Enable caching — Mark reusable tokens for discounts.
- Measure savings — Track reuse and effective reduction.
Choose a reasoning level per task
- Classify task — Trivial, moderate, or complex.
- Select effort — Minimal for speed; high for complexity.
- Validate outputs — Adjust if quality/latency lacking.
Build a conversation pricing estimator
- Collect tokens — Input, output, and reasoning tokens.
- Apply prices — Multiply by per-million rates.
- Account for caching — Discount eligible input tokens by 90%.
How-To Steps
All steps are labeled and presented in each How-To above.
Service
SoftwareApplication
Dataset
#dataset-redteam
Prompt-injection red-team assessment — System-level vulnerabilities across connectors and mitigations.
OfferCatalog
#pricing-catalog
- GPT-5
- GPT-5 Mini
- GPT-5 Nano
- Claude Opus 4.1
- Claude Sonnet 4
- Grok 4
- Gemini 2.5 Pro (>200k)
ListItem
OfferCatalog is composed of ListItems pointing to each product above.