In the Making It Interactive post on the LDBC blog, we were talking about composing an interactive Social Network Benchmark (SNB) metric. Now we will look at what this looks like in practice.
A benchmark is known by its primary metric. An actual benchmark implementation may deal with endless complexity but the whole point of the exercise is to reduce this all to an extremely compact form, optimally a number or two.
For SNB, we suggest clicks per second Interactive at scale (cpsI@ so many GB) as the primary metric. To each scale of the dataset corresponds a rate of update in the dataset's timeline (simulation time). When running the benchmark, the events in simulation time are transposed to a timeline in real time.
Another way of expressing the metric is therefore acceleration factor at scale. In this example, we run a 300 GB database at an acceleration of 1.64; i.e., in the present example, we did 97 minutes of simulation time in 58 minutes of real time.
Another key component of a benchmark is the full disclosure report (FDR). This is expected to enable any interested party to reproduce the experiment.
The system under test (SUT) is Virtuoso running an SQL implementation of the workload at 300 GB (SF = 300). This run gives an idea of what an official report will look like but is not one yet. The implementation differs from the present specification in the following:
The SNB test driver is not used. Instead, the workload is read from the file system by stored procedures on the SUT. This is done to circumvent latencies in update scheduling in the test driver which would result in the SUT not reaching full platform utilization.
The workload is extended by 2 short lookups, i.e., person profile view and post detail view. These are very short and serve to give the test more of an online flavor.
The short queries appear in the report as multiple entries. This should not be the case. This inflates the clicks per second number but does not significantly affect the acceleration factor.
As a caveat, this metric will not be comparable with future ones.
Aside from the composition of the report, the interesting point is that with the present workload, a 300 GB database keeps up with the simulation timeline on a commodity server, also when running updates. The query frequencies and run times are in the full report. We also produced a graphic showing the evolution of the throughput over a run of one hour --
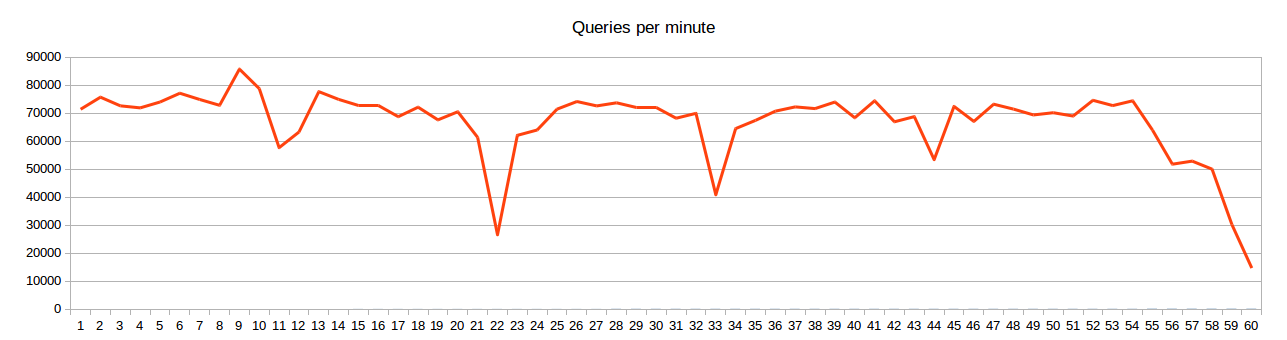
(click to embiggen)
We see steady throughput except for some slower minutes which correspond to database checkpoints. (A checkpoint, sometimes called a log checkpoint, is the operation which makes a database state durable outside of the transaction log.) If we run updates only at full platform, we get an acceleration of about 300x in memory for 20 minutes, then 10 minutes of nothing happening while the database is being checkpointed. This is measured with 6 2TB magnetic disks. Such a behavior is incompatible with an interactive workload. But with a checkpoint every 10 minutes and updates mixed with queries, checkpointing the database does not lead to impossible latencies. Thus, we do not get the TPC-C syndrome which requires tens of disks or several SSDs per core to run.
This is a good thing for the benchmark, as we do not want to require unusual I/O systems for competition. Such a requirement would simply encourage people to ignore the specification for the point and would limit the number of qualifying results.
The full report contains the details. This is also a template for later "real" FDRs. The supporting files are divided into test implementation and system configuration. With these materials plus the data generator, one should be able to repeat the results using a Virtuoso Open Source cut from v7fasttrack at github.com, feature/analytics branch.
In later posts we will analyze the results a bit more and see how much improvement potential we find. The next SNB article will be about the business intelligence and graph analytics areas of SNB.


![[cxml]](/fct/images/cxml_doc.png)
![[csv]](/fct/images/csv_doc.png)
![[text]](/fct/images/ntriples_doc.png)
![[turtle]](/fct/images/n3turtle_doc.png)
![[ld+json]](/fct/images/jsonld_doc.png)
![[rdf+json]](/fct/images/json_doc.png)
![[rdf+xml]](/fct/images/xml_doc.png)
![[atom+xml]](/fct/images/atom_doc.png)
![[html]](/fct/images/html_doc.png)


![[RDF Data]](/fct/images/sw-rdf-blue.png)