In recent times, a “Big Data” meme has emerged around three fundamental characteristics of data - Volume, Velocity, and Variety - all of which have been magnified by the hyper-connectivity unleashed by HTTP ubiquity as exemplified by the World Wide Web.
In addition to the original three V's, it has become abundantly clear that Veracity and Vulnerability are equally important characteristics which take the V-count of data to five.
These five V's have collectively triggered an important inflection regarding the nature of DBMS architecture and deployment topologies.
Loose-coupling of Database Management Systems (DBMS) and Database Files - moving from the traditional one-to-one association between a DBMS and its propriety Database Document Type, to a one-to-many association between a single DBMS and a variety of proprietary and/or open-standard Database Document Types (e.g., CSV, ORC, Avro, and others)
Extending Storage using Clusters of Database Files - where having a single Database Document File (sometimes striped across a number of disk controllers) as the focal point of storage has been typical, newer network-oriented filesystems (HDFS, Apache Spark, etc.) have emerged that enable the use of commodity hardware to construct vast clusters of Database Document Files that collectively increase data storage volume
Mapping the Content of Database Document Files to Relations - which are then operated on declaratively by a given DBMS using query languages, e.g., the Structured Query Language (SQL)
The net effect of all of this is that the most obvious Data Challenges posed by the five Vs are being addressed by more physical storage made available via the loose-coupling of DBMS application software and Database File storage. Unfortunately, this doesn't address the deeper issues at hand and doesn't offer real cost-savings (whether measured in energy consumption, environmental impact, or pure dollars) over the long haul.
Small Data as a solution to the challenges posed by the 5Vs of Data
“Small Data” introduces a new paradigm where puzzle-pieces are progressively discovered and applied to solve a puzzle. This approach leverages the power of Hyperdata (rather than Hypertext) - where hyperlinks function as “Super Keys” that offer a “deceptively simple” mechanism for modernizing the following:
Data Definition - every entity is unambiguously identified using a hyperlink and described using a 3-tuple structure (as opposed to the N-Tuple structure of traditional tables) where each part has a clear role based on existing “parts of speech” principles, i.e., subject, predicate, and object
Data Access and Flow - using identifiers that resolve to a description of whatever they identify ensures access and flow across traditional boundaries that underly all Data Silos (e.g., software applications, host operating systems, host machines, and networks)
Data Manipulation - using declarative query languages (e.g., SQL, SPARQL, or a combination of these, among others) to operate on data that flows across traditional boundaries as part of the solution production pipeline, i.e., constants and variables in the query body are resolved on an as-needed basis
Benefits?
Cost Savings - thanks to ubiquitous support of HTTP, you can refer to data from a variety of applications and services, wherever it might have been stored, and avoid building out new clusters of database documents spread over commodity hardware as a response to data volume
Performance & Scale -by leveraging innovations in cache-invalidation schemes and data compression, alongside the rapid increases in network bandwidth, to access and manipulate specific chunks of data
Data Privacy and Security - by fusing data representation with the logic that underlies entity descriptions (courtesy of the “predicate role” in “parts of speech”) access to data is controlled declaratively via fine-grained attribute-based access controls
Enhanced Agility - through a more flexible approach to data access and manipulation, avenues are opened up for addressing mission critical challenges such as skill discovery and management, knowledge base (or knowledge graph) construction, and cultural changes around data management that increase participation and allow easier and more privacy-aware monetization of data
How does it work?
Adherence to Linked Data Principles implies that Entities are Identified using hyperlinks (ideally, an HTTP URI due to the combined effects of resolvability and global ubiquity) and described using a 3-tuple structure comprising a Subject, Predicate, and Object.
Any user agent can look up (or "dereference") what that hyperlink identifies. This is the effect experienced when you click on that link in your browser, or use it as the target of a cURL command as shown below:
I can go much further, and construct actual subject→predicate→object sentences that collectively describe me, as the output of that cURL command demonstrates.
<> a foaf:PersonalProfileDocument ; foaf:maker :me ; foaf:primaryTopic :me .
:me a foaf:Person ; a schema:Person ; foaf:name "Kingsley Idehen" ; solid:account </> ; # link to the account uri solid:oidcIssuer <https://solid.openlinksw.com:8444> ; pim:storage </> ; # root storage ldp:inbox </inbox/> ; pim:preferencesFile </settings/prefs.ttl> ; # private settings/preferences solid:publicTypeIndex </settings/publicTypeIndex.ttl> ; solid:privateTypeIndex </settings/privateTypeIndex.ttl> .
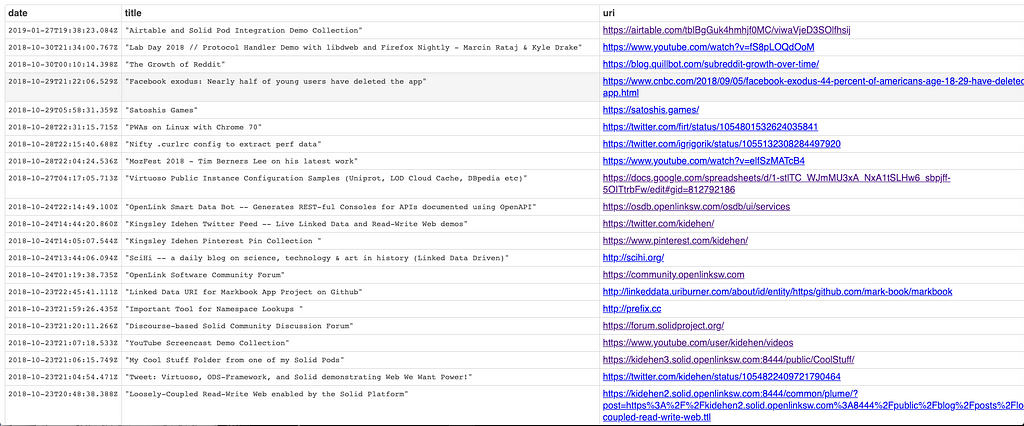
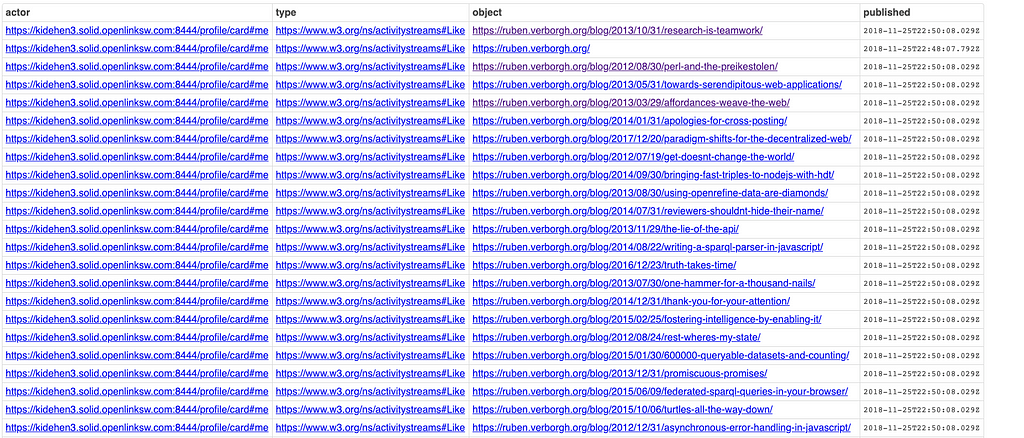
This basic principle also applies to Folders and the Files they contain, meaning that you have a massive collection of puzzle-pieces that describe a variety of things while also being amenable to progressive retrieval and association. In other words, puzzle-pieces come together on request, in response to specific actions like producing a solution to a query expressed in SPARQL.
Here's an example of a SPARQL Query (leveraging a Virtuoso pragma that conditionally invokes its built-in Crawler) that demonstrates this powerful feature based on the content of various combinations of Files and Folders.
## Invokes the Virtuoso Sponger Middleware DEFINE input:grab-all "yes"
SELECT DISTINCT ?o WHERE {
# SPARQL Query Body comprising URI-variables # and URI-constants
Small Data is Big Data that's Accessible (via Hyperlinks as Entity Identifiers) , Understandable (via Subject, Predicate, Object sentences that produce Hyperdata), and Actionable (REST-ful interactions with Actions that manifest as Hyperdata).
The net effect of this approach to data access, integration, and exploitation enables the construction of Knowledge Graphs that manifest progressively as a Semantic Web of Linked Data deployed across public and/or private networks (a/k/a Hybrid Clouds).



![[cxml]](/fct/images/cxml_doc.png)
![[csv]](/fct/images/csv_doc.png)
![[text]](/fct/images/ntriples_doc.png)
![[turtle]](/fct/images/n3turtle_doc.png)
![[ld+json]](/fct/images/jsonld_doc.png)
![[rdf+json]](/fct/images/json_doc.png)
![[rdf+xml]](/fct/images/xml_doc.png)
![[atom+xml]](/fct/images/atom_doc.png)
![[html]](/fct/images/html_doc.png)


![[RDF Data]](/fct/images/sw-rdf-blue.png)