The sweet spot of Web 3.0 (or any
other Web.vNext moniker) is all about providing Web Users with a
structured and interlinked data substrate that
facilitates serendipitous discovery of relevant "Things" i.e., a
Linked Data Web -- a Web of Linkable Entities that goes
beyond documents and other information resource (data containers)
types.
Understanding potential Linked Data Web business models, relative to other Web
based market segments, is best pursued via a BCG
Matrix diagram, such as the one I've constructed below:
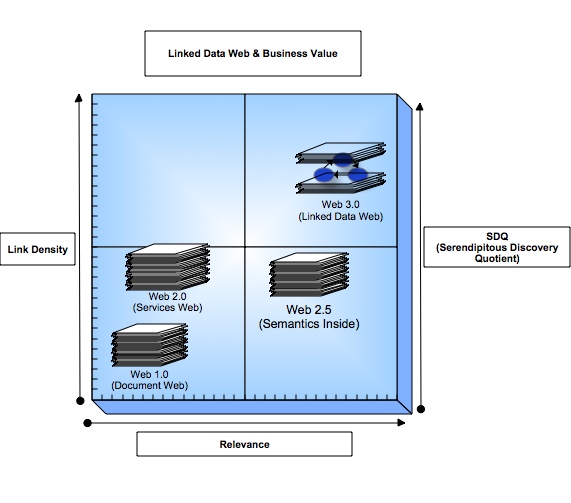
Notes:
Link Density
- Web 1.0's collection of "Web Sites" have relatively low link
density relative to Web 2.0's user-activity driven generation of
semi-structured linked data spaces (e.g., Blogs, Wikis,
Shared Bookmarks, RSS/Atom Feeds, Photo Galleries, Discussion
Forums etc..)
- Semantic Technologies (i.e. "Semantics Inside
style solutions") which are primarily about "Semantic Meaning"
culled from Web 1.0 Pages also have limited linked density relative
to Web 2.0
- The Linked Data Web, courtesy of the open-ended linking
capacity of URIs, matches and ultimately exceeds Web 2.0 link
density.
Relevance
- Web 1.0 and 2.0 are low relevance realms driven by hyperlinks
to information resources ((X)HTML, RSS, Atom,
OPML, XML, Images, Audio files etc.) associated with Literal Labels
and Tagging schemes devoid of explicit property based resource
description thereby making the pursuit of relevance mercurial at
best
- Semantic Technologies offer more relevance than Web 1.0 and 2.0
based on the increased context that semantic analysis of Web pages
accords
- The Linked Data Web, courtesy of URIs that expose
self-describing data entities, match the relevance levels attained
by Semantic Technologies.
Serendipity Quotient (SDQ)
- Web 1.0 has next to no serendipity, the closest thing is
Google's "I'm
Feeling Lucky" button
- Web 2.0 possess higher potential for serendipitous discovery
than Web 1.0, but such potential is neutralized by inherent
subjectivity due to its human-interaction-focused literal
foundation (e.g., tags, voting schemes, wiki editors etc.)
- Semantic Technologies produce islands-of-relevance with little
scope for serendipitous discovery due to URI invisibility, since the prime focus is
delivering more context to Web search relative to traditional
Web 1.0 search engines.
- The Linked Data Web's use of URIs as the naming and
resolution mechanism for exposing structured and interlinked
resources provides the highest potential for serendipitous
discovery of relevant "Things"
To conclude, the Linked Data Web's market opportunities are all about
the evolution of the Web into a powerful substrate that offers a
unique intersection of "Link Density" and "Relevance", exploitable
across horizontal and vertical market segments to solutions
providers. Put differently, SDQ is how you take "The Ad" out of
"Advertising" when matching Web users to relevant things :-)