Details
Kingsley Uyi Idehen
Lexington, United States
Subscribe
Post Categories
Subscribe
Recent Articles
Display Settings
|
Virtuoso Linked Data Deployment 3-Step
Injecting Linked Data into the Web has been a major pain point for those who seek personal, service, or organization-specific variants of DBpedia. Basically, the sequence goes something like this:
-
You encounter DBpedia or the LOD Cloud Pictorial.
-
You look around (typically following your nose from link to link).
-
You attempt to publish your own stuff.
-
You get stuck.
The problems typically take the following form:
-
Functionality confusion about the complementary Name and Address functionality of a single URI abstraction
-
Terminology confusion due to conflation and over-loading of terms such as Resource, URL, Representation, Document, etc.
-
Inability to find robust tools with which to generate Linked Data from existing data sources such as relational databases, CSV files, XML, Web Services, etc.
To start addressing these problems, here is a simple guide for generating and publishing Linked Data using Virtuoso.
Step 1 - RDF Data Generation
Existing RDF data can be added to the Virtuoso RDF Quad Store via a variety of built-in data loader utilities.
Many options allow you to easily and quickly generate RDF data from other data sources:
-
Install the Sponger Bookmarklet for the URIBurner service. Bind this to your own SPARQL-compliant backend RDF database (in this scenario, your local Virtuoso instance), and then Sponge some HTTP-accessible resources.
-
Convert relational DBMS data to RDF using the Virtuoso RDF Views Wizard.
-
Starting with CSV files, you can
- Place them at an HTTP-accessible location, and use the Virtuoso Sponger to convert them to RDF or;
-
Use the CVS import feature to import their content into Virtuoso's relational data engine; then use the built-in RDF Views Wizard as with other RDBMS data.
-
Starting from XML files, you can
-
Use Virtuoso's inbuilt XSLT-Processor for manual XML to RDF/XML transformation or;
- Leverage the Sponger Cartridge for GRDDL, if there is a transformation service associated with your XML data source, or;
- Let the Sponger analyze the XML data source and make a best-effort transformation to RDF.
Step 2 - Linked Data Deployment
Install the Faceted Browser VAD package (fct_dav.vad) which delivers the following:
-
Faceted Browser Engine UI
-
Dynamic Hypermedia Resource Generator
- delivers descriptor resources for every entity (data object) in the Native or Virtual Quad Stores
- supports a broad array of output formats, including HTML+RDFa, RDF/XML, N3/Turtle, NTriples, RDF-JSON, OData+Atom, and OData+JSON.
Step 3 - Linked Data Consumption & Exploitation
Three simple steps allow you, your enterprise, and your customers to consume and exploit your newly deployed Linked Data --
-
Load a page like this in your browser:
http://<cname>[:<port>]/describe/?uri=<entity-uri>
-
<cname>[:<port>] gets replaced by the host and port of your Virtuoso instance
-
<entity-uri> gets replaced by the URI you want to see described -- for instance, the URI of one of the resources you let the Sponger handle.
-
Follow the links presented in the descriptor page.
- If you ever see a blank page with a hyperlink subject name in the About: section at the top of the page, simply add the parameter "&sp=1" to the URL in the browser's Address box, and hit [ENTER]. This will result in an "on the fly" resource retrieval, transformation, and descriptor page generation.
-
Use the navigator controls to page up and down the data associated with the "in scope" resource descriptor.
Related
|
10/29/2010 18:54 GMT-0500
|
Modified:
11/02/2010 11:57 GMT-0500
|
Virtuoso Linked Data Deployment In 3 Simple Steps
Injecting Linked Data into the Web has been a major pain point for those who seek personal, service, or organization-specific variants of DBpedia. Basically, the sequence goes something like this:
-
You encounter DBpedia or the LOD Cloud Pictorial.
-
You look around (typically following your nose from link to link).
-
You attempt to publish your own stuff.
-
You get stuck.
The problems typically take the following form:
-
Functionality confusion about the complementary Name and Address functionality of a single URI abstraction
-
Terminology confusion due to conflation and over-loading of terms such as Resource, URL, Representation, Document, etc.
-
Inability to find robust tools with which to generate Linked Data from existing data sources such as relational databases, CSV files, XML, Web Services, etc.
To start addressing these problems, here is a simple guide for generating and publishing Linked Data using Virtuoso.
Step 1 - RDF Data Generation
Existing RDF data can be added to the Virtuoso RDF Quad Store via a variety of built-in data loader utilities.
Many options allow you to easily and quickly generate RDF data from other data sources:
-
Install the Sponger Bookmarklet for the URIBurner service. Bind this to your own SPARQL-compliant backend RDF database (in this scenario, your local Virtuoso instance), and then Sponge some HTTP-accessible resources.
-
Convert relational DBMS data to RDF using the Virtuoso RDF Views Wizard.
-
Starting with CSV files, you can
- Place them at an HTTP-accessible location, and use the Virtuoso Sponger to convert them to RDF or;
-
Use the CVS import feature to import their content into Virtuoso's relational data engine; then use the built-in RDF Views Wizard as with other RDBMS data.
-
Starting from XML files, you can
-
Use Virtuoso's inbuilt XSLT-Processor for manual XML to RDF/XML transformation or;
- Leverage the Sponger Cartridge for GRDDL, if there is a transformation service associated with your XML data source, or;
- Let the Sponger analyze the XML data source and make a best-effort transformation to RDF.
Step 2 - Linked Data Deployment
Install the Faceted Browser VAD package (fct_dav.vad) which delivers the following:
-
Faceted Browser Engine UI
-
Dynamic Hypermedia Resource Generator
- delivers descriptor resources for every entity (data object) in the Native or Virtual Quad Stores
- supports a broad array of output formats, including HTML+RDFa, RDF/XML, N3/Turtle, NTriples, RDF-JSON, OData+Atom, and OData+JSON.
Step 3 - Linked Data Consumption & Exploitation
Three simple steps allow you, your enterprise, and your customers to consume and exploit your newly deployed Linked Data --
-
Load a page like this in your browser:
http://<cname>[:<port>]/describe/?uri=<entity-uri>
-
<cname>[:<port>] gets replaced by the host and port of your Virtuoso instance
-
<entity-uri> gets replaced by the URI you want to see described -- for instance, the URI of one of the resources you let the Sponger handle.
-
Follow the links presented in the descriptor page.
- If you ever see a blank page with a hyperlink subject name in the About: section at the top of the page, simply add the parameter "&sp=1" to the URL in the browser's Address box, and hit [ENTER]. This will result in an "on the fly" resource retrieval, transformation, and descriptor page generation.
-
Use the navigator controls to page up and down the data associated with the "in scope" resource descriptor.
Related
|
10/29/2010 18:54 GMT-0500
|
Modified:
11/02/2010 11:55 GMT-0500
|
URIBurner: Painless Generation & Exploitation of Linked Data (Update 1 - Demo Links Added)
What is URIBurner?
A service from OpenLink Software, available at: http://uriburner.com, that enables anyone to generate structured descriptions -on the fly- for resources that are already published to HTTP based networks. These descriptions exist as hypermedia resource representations where links are used to identify:
-
the entity (data object or datum) being described,
- each of its attributes, and
- each of its attributes values (optionally).
The hypermedia resource representation outlined above is what is commonly known as an Entity-Attribute-Value (EAV) Graph. The use of generic HTTP scheme based Identifiers is what distinguishes this type of hypermedia resource from others.
Why is it Important?
The virtues (dual pronged serendipitous discovery) of publishing HTTP based Linked Data across public (World Wide Web) or private (Intranets and/or Extranets) is rapidly becoming clearer to everyone. That said, the nuance laced nature of Linked Data publishing presents significant challenges to most. Thus, for Linked Data to really blossom the process of publishing needs to be simplified i.e., "just click and go" (for human interaction) or REST-ful orchestration of HTTP CRUD (Create, Read, Update, Delete) operations between Client Applications and Linked Data Servers.
How Do I Use It?
In similar vane to the role played by FeedBurner with regards to Atom and RSS feed generation, during the early stages of the Blogosphere, it enables anyone to publish Linked Data bearing hypermedia resources on an HTTP network. Thus, its usage covers two profiles: Content Publisher and Content Consumer.
Content Publisher
The steps that follow cover all you need to do:
- place a tag within your HTTP based hypermedia resource (e.g. within section for HTML )
- use a URL via the @href attribute value to identify the location of the structured description of your resource, in this case it takes the form: http://linkeddata.uriburner.com/about/id/{scheme-or-protocol}/{your-hostname-or-authority}/{your-local-resource}
- for human visibility you may consider adding associating a button (as you do with Atom and RSS) with the URL above.
That's it! The discoverability (SDQ) of your content has just multiplied significantly, its structured description is now part of the Linked Data Cloud with a reference back to your site (which is now a bona fide HTTP based Linked Data Space).
Examples
HTML+RDFa based representation of a structured resource description:
<link rel="describedby" title="Resource Description (HTML)"type="text/html" href="http://linkeddata.uriburner.com/about/id/http/example.org/xyz.html"/>
JSON based representation of a structured resource description:
<link rel="describedby" title="Resource Description (JSON)" type="application/json" href="http://linkeddata.uriburner.com/about/id/http/example.org/xyz.html"/>
N3 based representation of a structured resource description:
<link rel="describedby" title="Resource Description (N3)" type="text/n3" href="http://linkeddata.uriburner.com/about/id/http/example.org/xyz.html"/>
RDF/XML based representations of a structured resource description:
<link rel="describedby" title="Resource Description (RDF/XML)" type="application/rdf+xml" href="http://linkeddata.uriburner.com/about/id/http/example.org/xyz.html"/>
Content Consumer
As an end-user, obtaining a structured description of any resource published to an HTTP network boils down to the following steps:
- go to: http://uriburner.com
- drag the Page Metadata Bookmarklet link to your Browser's toolbar
- whenever you encounter a resource of interest (e.g. an HTML page) simply click on the Bookmarklet
- you will be presented with an HTML representation of a structured resource description (i.e., identifier of the entity being described, its attributes, and its attribute values will be clearly presented).
Examples
If you are a developer, you can simply perform an HTTP operation request (from your development environment of choice) using any of the URL patterns presented below:
HTML:
- curl -I -H "Accept: text/html" http://linkeddata.uriburner.com/about/id/{scheme}/{authority}/{local-path}
JSON:
- curl -I -H "Accept: application/json" http://linkeddata.uriburner.com/about/id/{scheme}/{authority}/{local-path}
- curl http://linkeddata.uriburner.com/about/data/json/{scheme}/{authority}/{local-path}
Notation 3 (N3):
-
curl -I -H "Accept: text/n3" http://linkeddata.uriburner.com/about/id/{scheme}/{authority}/{local-path}
-
curl http://linkeddata.uriburner.com/about/data/n3/{scheme}/{authority}/{local-path}
-
curl -I -H "Accept: text/turtle" http://linkeddata.uriburner.com/about/id/{scheme}/{authority}/{local-path}
-
curl http://linkeddata.uriburner.com/about/data/ttl/{scheme}/{authority}/{local-path}
RDF/XML:
-
curl -I -H "Accept: application/rdf+xml" http://linkeddata.uriburner.com/about/id/{scheme}/{authority}/{local-path}
-
curl http://linkeddata.uriburner.com/about/data/xml/{scheme}/{authority}/{local-path}
Conclusion
URIBurner is a "deceptively simple" solution for cost-effective exploitation of HTTP based Linked Data meshes. It doesn't require any programming or customization en route to immediately realizing its virtues.
If you like what URIBurner offers, but prefer to leverage its capabilities within your domain -- such that resource description URLs reside in your domain, all you have to do is perform the following steps:
-
download a copy of Virtuoso (for local desktop, workgroup, or data center installation) or
- instantiate Virtuoso via the Amazon EC2 Cloud
- enable the Sponger Middleware component via the RDF Mapper VAD package (which includes cartridges for over 30 different resources types)
When you install your own URIBurner instances, you also have the ability to perform customizations that increase resource description fidelity in line with your specific needs. All you need to do is develop a custom extractor cartridge and/or meta cartridge.
Related:
|
03/10/2010 12:52 GMT-0500
|
Modified:
03/11/2010 10:16 GMT-0500
|
Revisiting HTTP based Linked Data (Update 1 - Demo Video Links Added)
Motivation for this post arose from a series of Twitter exchanges between Tony Hirst and I, in relation to his blog post titled: So What Is It About Linked Data that Makes it Linked Data™ ?
At the end of the marathon session, it was clear to me that a blog post was required for future reference, at the very least :-)
"Data Access by Reference" mechanism for Data Objects (or Entities) on HTTP networks. It enables you to Identify a Data Object and Access its structured Data Representation via a single Generic HTTP scheme based Identifier (HTTP URI). Data Object representation formats may vary; but in all cases, they are hypermedia oriented, fully structured, and negotiable within the context of a client-server message exchange.
Why is it Important?
Information makes the world tick!
Information doesn't exist without data to contextualize.
Information is inaccessible without a projection (presentation) medium.
All information (without exception, when produced by humans) is subjective. Thus, to truly maximize the innate heterogeneity of collective human intelligence, loose coupling of our information and associated data sources is imperative.
How is Linked Data Delivered?
Linked Data is exposed to HTTP networks (e.g. World Wide Web) via hypermedia resources bearing structured representations of data object descriptions. Remember, you have a single Identifier abstraction (generic HTTP URI) that embodies: Data Object Name and Data Representation Location (aka URL).
How are Linked Data Object Representations Structured?
A structured representation of data exists when an Entity (Datum), its Attributes, and its Attribute Values are clearly discernible. In the case of a Linked Data Object, structured descriptions take the form of a hypermedia based Entity-Attribute-Value (EAV) graph pictorial -- where each Entity, its Attributes, and its Attribute Values (optionally) are identified using Generic HTTP URIs.
Examples of structured data representation formats (content types) associated with Linked Data Objects include:
- text/html
- text/turtle
- text/n3
- application/json
- application/rdf+xml
- Others
How Do I Create Linked Data oriented Hypermedia Resources?
You markup resources by expressing distinct entity-attribute-value statements (basically these a 3-tuple records) using a variety of notations:
- (X)HTML+RDFa,
-
JSON,
-
Turtle,
-
N3,
-
TriX,
-
TriG,
-
RDF/XML, and
- Others (for instance you can use Atom data format extensions to model EAV graph as per OData initiative from Microsoft).
You can achieve this task using any of the following approaches:
- Notepad
- WYSIWYG Editor
- Transformation of Database Records via Middleware
- Transformation of XML based Web Services output via Middleware
- Transformation of other Hypermedia Resources via Middleware
- Transformation of non Hypermedia Resources via Middleware
- Use a platform that delivers all of the above.
Practical Examples of Linked Data Objects Enable
- Describe Who You Are, What You Offer, and What You Need via your structured profile, then leave your HTTP network to perform the REST (serendipitous discovery of relevant things)
- Identify (via map overlay) all items of interest based on a 2km+ radious of my current location (this could include vendor offerings or services sought by existing or future customers)
- Share the latest and greatest family photos with family members *only* without forcing them to signup for Yet Another Web 2.0 service or Social Network
- No repetitive signup and username and password based login sequences per Web 2.0 or Mobile Application combo
- Going beyond imprecise Keyword Search to the new frontier of Precision Find - Example, Find Data Objects associated with the keywords: Tiger, while enabling the seeker disambiguate across the "Who", "What", "Where", "When" dimensions (with negation capability)
- Determine how two Data Objects are Connected - person to person, person to subject matter etc. (LinkedIn outside the walled garden)
- Use any resource address (e.g blog or bookmark URL) as the conduit into a Data Object mesh that exposes all associated Entities and their social network relationships
- Apply patterns (social dimensions) above to traditional enterprise data sources in combination (optionally) with external data without compromising security etc.
How Do OpenLink Software Products Enable Linked Data Exploitation?
Our data access middleware heritage (which spans 16+ years) has enabled us to assemble a rich portfolio of coherently integrated products that enable cost-effective evaluation and utilization of Linked Data, without writing a single line of code, or exposing you to the hidden, but extensive admin and configuration costs. Post installation, the benefits of Linked Data simply materialize (along the lines described above).
Our main Linked Data oriented products include:
-
OpenLink Data Explorer -- visualizes Linked Data or Linked Data transformed "on the fly" from hypermedia and non hypermedia data sources
-
URIBurner -- a "deceptively simple" solution that enables the generation of Linked Data "on the fly" from a broad collection of data sources and resource types
-
OpenLink Data Spaces -- a platform for enterprises and individuals that enhances distributed collaboration via Linked Data driven virtualization of data across its native and/or 3rd party content manager for: Blogs, Wikis, Shared Bookmarks, Discussion Forums, Social Networks etc
-
OpenLink Virtuoso -- a secure and high-performance native hybrid data server (Relational, RDF-Graph, Document models) that includes in-built Linked Data transformation middleware (aka. Sponger).
Related
|
03/04/2010 10:16 GMT-0500
|
Modified:
03/08/2010 09:59 GMT-0500
|
Linked Data & Socially Enhanced Collaboration (Enterprise or Individual) -- Update 1
Socially enhanced enterprise and invididual collaboration is becoming a focal point for a variety of solutions that offer erswhile distinct content managment features across the realms of Blogging, Wikis, Shared Bookmarks, Discussion Forums etc.. as part of an integrated platform suite. Recently, Socialtext has caught my attention courtesy of its nice features and benefits page . In addition, I've also found the Mike 2.0 portal immensely interesting and valuable, for those with an enterprise collaboration bent.
Anyway, Socialtext and Mike 2.0 (they aren't identical and juxtaposition isn't seeking to imply this) provide nice demonstrations of socially enhanced collaboration for individuals and/or enterprises is all about:
- Identifying Yourself
- Identifying Others (key contributors, peers, collaborators)
- Serendipitous Discovery of key contributors, peers, and collaborators
- Serendipitous Discovery by key contributors, peers, and collaborators
- Develop and sustain relationships via socially enhanced professional network hybrid
- Utilize your new "trusted network" (which you've personally indexed) when seeking help or propagating a meme.
As is typically the case in this emerging realm, the critical issue of discrete "identifiers" (record keys in sense) for data items, data containers, and data creators (individuals and groups) is overlooked albeit unintentionally.
How HTTP based Linked Data Addresses the Identifier Issue
Rather than using platform constrained identifiers such as:
- email address (a "mailto" scheme identifier),
- a dbms user account,
- application specific account, or
- OpenID.
It enables you to leverage the platform independence of HTTP scheme Identifiers (Generic URIs) such that Identifiers for:
- You,
- Your Peers,
- Your Groups, and
- Your Activity Generated Data,
simply become conduits into a mesh of HTTP -- referencable and accessible -- Linked Data Objects endowed with High SDQ (Serendipitious Discovery Quotient). For example my Personal WebID is all anyone needs to know if they want to explore:
- My Profile (which includes references to data objects associated with my interests, social-network, calendar, bookmarks etc.)
- Data generated by my activities across various data spaces (via data objects associated with my online accounts e.g. Del.icio.us, Twitter, Last.FM)
-
Linked Data Meshups via URIBurner (or any other Virtuoso instance) that provide an extend view of my profile
How FOAF+SSL adds Socially aware Security
Even when you reach a point of equilibrium where: your daily activities trigger orchestratestration of CRUD (Create, Read, Update, Delete) operations against Linked Data Objects within your socially enhanced collaboration network, you still have to deal with the thorny issues of security, that includes the following:
- Single Sign On,
- Authentication, and
- Data Access Policies.
FOAF+SSL, an application of HTTP based Linked Data, enables you to enhance your Personal HTTP scheme based Identifer (or WebID) via the following steps (peformed by a FOAF+SSL compliant platform):
- Imprint WebID within a self-signed x.509 based public key (certificate) associated with your private key (generated by FOAF+SSL platform or manually via OpenSSL)
- Store public key components (modulous and exponent) into your FOAF based profile document which references your Personal HTTP Identifier as its primary topic
- Leverage HTTP URL component of WebID for making public key components (modulous and exponent) available for x.509 certificate based authentication challenges posed by systems secured by FOAF+SSL (directly) or OpenID (indirectly via FOAF+SSL to OpenID proxy services).
Contrary to conventional experiences with all things PKI (Public Key Infrastructure) related, FOAF+SSL compliant platforms typically handle the PKI issues as part of the protocol implementation; thereby protecting you from any administrative tedium without compromising security.
Conclusions
Understanding how new technology innovations address long standing problems, or understanding how new solutions inadvertently fail to address old problems, provides time tested mechanisms for product selection and value proposition comprehension that ultimately save scarce resources such as time and money.
If you want to understand real world problem solution #1 with regards to HTTP based Linked Data look no further than the issues of secure, socially aware, and platform independent identifiers for data objects, that build bridges across erstwhile data silos.
If you want to cost-effectively experience what I've outlined in this post, take a look at OpenLink Data Spaces (ODS) which is a distributed collaboration engine (enterprise of individual) built around the Virtuoso database engines. It simply enhances existing collaboration tools via the following capabilities:
Addition of Social Dimensions via HTTP based Data Object Identifiers for all Data Items (if missing)
- Ability to integrate across a myriad of Data Source Types rather than a select few across RDBM Engines, LDAP, Web Services, and various HTTP accessible Resources (Hypermedia or Non Hypermedia content types)
- Addition of FOAF+SSL based authentication
- Addition of FOAF+SSL based Access Control Lists (ACLs) for policy based data access.
Related:
|
03/02/2010 15:47 GMT-0500
|
Modified:
03/03/2010 19:50 GMT-0500
|
Take N: Yet Another OpenLink Data Spaces Introduction
Problem:
Your Life, Profession, Web, and Internet do not need to become mutually exclusive due to "information overload".
Solution:
A platform or service that delivers a point of online presence that embodies the fundamental separation of: Identity, Data Access, Data Representation, Data Presentation, by adhering to Web and Internet protocols.
How:
Typical post installation (Local or Cloud) task sequence:
-
Identify myself (happens automatically by way of registration)
- If in an LDAP environment, import accounts or associate system with LDAP for account lookup and authentication
-
Identify Online Accounts (by fleshing out profile) which also connects system to online accounts and their data
- Use Profile for granular description (Biography, Interests, WishList, OfferList, etc.)
- Optionally upstream or downstream data to and from my online accounts
- Create content Tagging Rules
- Create rules for associating Tags with formal URIs
- Create automatic Hyperlinking Rules for reuse when new content is created (e.g. Blog posts)
- Exploit Data Portability virtues of RSS, Atom, OPML, RDFa, RDF/XML, and other formats for imports and exports
- Automatically tag imported content
- Use function-specific helper application UIs for domain specific data generation e.g. AddressBook (optionally use vCard import), Calendar (optionally use iCalendar import), Email, File Storage (use WebDAV mount with copy and paste or HTTP GET), Feed Subscriptions (optionally import RSS/Atom/OPML feeds), Bookmarking (optionally import bookmark.html or XBEL) etc..
- Optionally enable "Conversation" feature (today: Social Media feature) across the relevant application domains (manage conversations under covers using NNTP, the standard for this functionality realm)
- Generate HTTP based Entity IDs (URIs) for every piece of data in this burgeoning data space
- Use REST based APIs to perform CRUD tasks against my data (local and remote) (SPARQL, GData, Ubiquity Commands, Atom Publishing)
- Use OpenID, OAuth, FOAF+SSL, FOAF+SSL+OpenID for accessing data elsewhere
- Use OpenID, OAuth, FOAF+SSL, FOAF+SSL+OpenID for Controlling access to my data (Self Signed Certificate Generation, Browser Import of said Certificate & associated Private Key, plus persistence of Certificate to FOAF based profile data space in "one click")
- Have a simple UI for Entity-Attribute-Value or Subject-Predicate-Object arbitrary data annotations and creation since you can't pre model an "Open World" where the only constant is data flow
- Have my Personal URI (Web ID) as the single entry point for controlled access to my HTTP accessible data space
I've just outlined a snippet of the capabilities of the OpenLink Data Spaces platform. A platform built using OpenLink Virtuoso, architected to deliver: open, platform independent, multi-model, data access and data management across heterogeneous data sources.
All you need to remember is your URI when seeking to interact with your data space.
Related
-
Get Yourself a URI (Web ID) in 5 Minutes or Less!
-
Various posts over the years about Data Spaces
-
Future of Desktop Post
-
Simplify My Life Post by Bengee Nowack
|
04/22/2009 14:46 GMT-0500
|
Modified:
04/22/2009 15:32 GMT-0500
|
Introducing Virtuoso Universal Server (Cloud Edition) for Amazon EC2
What is it?
A pre-installed edition of Virtuoso for Amazon's EC2 Cloud platform.
What does it offer?
From a Web Entrepreneur perspective it offers:
-
Low cost entry point to a game-changing Web 3.0+ (and beyond) platform that combines SQL, RDF, XML, and Web Services functionality
-
Flexible variable cost model (courtesy of EC2 DevPay) tightly bound to revenue generated by your services
-
Delivers federated and/or centralized model flexibility for you SaaS based solutions
-
Simple entry point for developing and deploying sophisticated database driven applications (SQL or RDF Linked Data Web oriented)
-
Complete framework for exploiting OpenID, OAuth (including Role enhancements) that simplifies exploitation of these vital Identity and Data Access technologies
- Easily implement RDF Linked Data based Mail, Blogging, Wikis, Bookmarks, Calendaring, Discussion Forums, Tagging, Social-Networking as Data Space (data containers) features of your application or service offering
- Instant alleviation of challenges (e.g. service costs and agility) associated with Data Portability and Open Data Access across Web 2.0 data silos
-
LDAP integration for Intranet / Extranet style applications.
From the DBMS engine perspective it provides you with one or more pre-configured instances of Virtuoso that enable immediate exploitation of the following services:
-
RDF Database (a Quad Store with SPARQL & SPARUL Language & Protocol support)
-
SQL Database (with ODBC, JDBC, OLE-DB, ADO.NET, and XMLA driver access)
- XML Database (XML Schema, XQuery/Xpath, XSLT, Full Text Indexing)
- Full Text Indexing.
From a Middleware perspective it provides:
-
RDF Views (Wrappers / Semantic Covers) over SQL, XML, and other data sources accessible via SOAP or REST style Web Services
-
Sponger Service for converting non RDF information resources into RDF Linked Data "on the fly" via a large collection of pre-installed RDFizer Cartridges.
From the Web Server Platform perspective it provides an alternative to LAMP stack components such as MySQL and Apace by offering
-
HTTP Web Server
-
WebDAV Server
-
Web Application Server (includes PHP runtime hosting)
-
SOAP or REST style Web Services Deployment
-
RDF Linked Data Deployment
-
SPARQL (SPARQL Query Language) and SPARUL (SPARQL Update Language) endpoints
- Virtuoso Hosted PHP packages for MediaWiki, Drupal, Wordpress, and phpBB3 (just install the relevant Virtuoso Distro. Package).
From the general System Administrator's perspective it provides:
-
Online Backups (Backup Set dispatched to S3 buckets, FTP, or HTTP/WebDAV server locations)
- Synchronized Incremental Backups to Backup Set locations
- Backup Restore from Backup Set location (without exiting to EC2 shell).
Higher level user oriented offerings include:
- OpenLink Data Explorer front-end for exploring the burgeoning Linked Data Web
-
Ajax based SPARQL Query Builder (iSPARQL) that enables SPARQL Query construction by Example
- Ajax based SQL Query Builder (QBE) that enables SQL Query construction by Example.
For Web 2.0 / 3.0 users, developers, and entrepreneurs it offers it includes Distributed Collaboration Tools & Social Media realm functionality courtesy of ODS that includes:
-
Point of presence on the Linked Data Web that meshes your Identity and your Data via URIs
-
System generated Social Network Profile & Contact Data via FOAF?
-
System generated SIOC (Semantically Interconnected Online Community) Data Space (that includes a Social Graph) exposing all your Web data in RDF Linked Data form
-
System generated OpenID and automatic integration with FOAF
-
Transparent Data Integration across Facebook, Digg, LinkedIn, FriendFeed, Twitter, and any other Web 2.0 data space equipped with RSS / Atom support and/or REST style Web Services
-
In-built support for SyncML which enables data synchronization with Mobile Phones.
How Do I Get Going with It?
|
11/28/2008 19:27 GMT-0500
|
Modified:
11/28/2008 16:06 GMT-0500
|
Dynamic Linked Data Constellation
Now that the virtues of dynamic generation of RDF based Linked Data are becoming clearer, I guess it's time to unveil the Virtuoso Sponger driven Dynamic Linked Data constellation diagram.
Our diagram depicts the myriad of data sources from which RDF Linked Data is generated "on the fly" via our data source specific RDF-zation cartridges/drivers. It also unveils how the sponger leverages the Linked Data constellations of UMBEL, DBpedia, Bio2Rdf, and others for lookups.

|
10/09/2008 21:23 GMT-0500
|
Modified:
10/17/2008 10:45 GMT-0500
|
What is Linked Data oriented RDF-ization?
RDF-ization is a term used by the Semantic Web community to describe the process of generating RDF from non RDF Data Sources such as (X)HTML, Weblogs, Shared Bookmark Collections, Photo Galleries, Calendars, Contact Managers, Feed Subscriptions, Wikis, and other information resource collections.
If the RDF generated, results in an entity-to-entity level network (graph) in which each entity is endowed with a de-referencable HTTP based ID (a URI), we end up with an enhancement to the Web that adds Hyperdata linking across extracted entities, to the existing Hypertext based Web of linked documents (pages, images, and other information resource types). Thus, I can use the same URL linking mechanism to reference a broader range of "Things" i.e., documents, things that documents are about, or things loosely associated with documents.
The Virtuoso Sponger is an example of an RDF Middleware solution from OpenLink Software. It's an in-built component of the Virtuoso Universal Server, and deployable in many forms e.g., Software as Service (SaaS) or traditional software installation. It delivers RDF-ization services via a collection of Web information resource specific Cartridges/Providers/Drivers covering Wikipedia, Freebase, CrunchBase, WikiCompany, OpenLibrary, Digg, eBay, Amazon, RSS/Atom/OPML feed sources, XBRL, and many more.
RDF-ization alone doesn't ensure valuable RDF based Linked Data on the Web. The process of producing RDF Linked Data is ultimately about the art of effectively describing resources with an eye for context.
RDF-ization Processing Steps
-
Entity Extraction
-
Vocabulary/Schema/Ontology (Data Dictionary) mapping
-
HTTP based Proxy URI generation
- Linked Data Cloud Lookups (e.g., perform UMBEL lookup to add "isAbout" fidelity to graph and then lookup DBpedia and other LOD instance data enclaves for Identical individuals and connect via "owl:sameAs")
-
RDF Linked Data Graph projection that uses the description of the container information resource to expose the URIs of the distilled entities.
The animation that follows illustrates the process (5,000 feet view), from grabbing resources via HTTP GET, to injecting RDF Linked Data back into the Web cloud:
Note: the Shredder is a Generic Cartridge, so you would have one of these per data source type (information resource type).
|
10/06/2008 20:14 GMT-0500
|
Modified:
10/07/2008 17:35 GMT-0500
|
The Linked Data Market via a BCG Matrix (Updated)
The sweet spot of Web 3.0 (or any other Web.vNext moniker) is all about providing Web Users with a structured and interlinked data substrate that facilitates serendipitous discovery of relevant "Things" i.e., a Linked Data Web -- a Web of Linkable Entities that goes beyond documents and other information resource (data containers) types.
Understanding potential Linked Data Web business models, relative to other Web based market segments, is best pursued via a BCG Matrix diagram, such as the one I've constructed below:
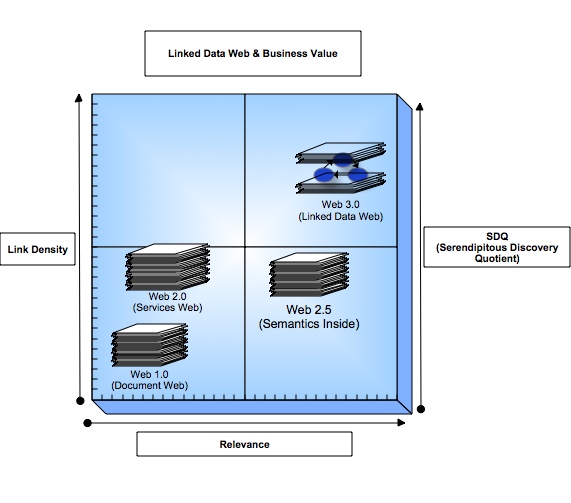
Notes:
Link Density
- Web 1.0's collection of "Web Sites" have relatively low link density relative to Web 2.0's user-activity driven generation of semi-structured linked data spaces (e.g., Blogs, Wikis, Shared Bookmarks, RSS/Atom Feeds, Photo Galleries, Discussion Forums etc..)
- Semantic Technologies (i.e. "Semantics Inside style solutions") which are primarily about "Semantic Meaning" culled from Web 1.0 Pages also have limited linked density relative to Web 2.0
- The Linked Data Web, courtesy of the open-ended linking capacity of URIs, matches and ultimately exceeds Web 2.0 link density.
Relevance
- Web 1.0 and 2.0 are low relevance realms driven by hyperlinks to information resources ((X)HTML, RSS, Atom, OPML, XML, Images, Audio files etc.) associated with Literal Labels and Tagging schemes devoid of explicit property based resource description thereby making the pursuit of relevance mercurial at best
- Semantic Technologies offer more relevance than Web 1.0 and 2.0 based on the increased context that semantic analysis of Web pages accords
- The Linked Data Web, courtesy of URIs that expose self-describing data entities, match the relevance levels attained by Semantic Technologies.
Serendipity Quotient (SDQ)
- Web 1.0 has next to no serendipity, the closest thing is Google's "I'm Feeling Lucky" button
- Web 2.0 possess higher potential for serendipitous discovery than Web 1.0, but such potential is neutralized by inherent subjectivity due to its human-interaction-focused literal foundation (e.g., tags, voting schemes, wiki editors etc.)
- Semantic Technologies produce islands-of-relevance with little scope for serendipitous discovery due to URI invisibility, since the prime focus is delivering more context to Web search relative to traditional Web 1.0 search engines.
- The Linked Data Web's use of URIs as the naming and resolution mechanism for exposing structured and interlinked resources provides the highest potential for serendipitous discovery of relevant "Things"
To conclude, the Linked Data Web's market opportunities are all about the evolution of the Web into a powerful substrate that offers a unique intersection of "Link Density" and "Relevance", exploitable across horizontal and vertical market segments to solutions providers. Put differently, SDQ is how you take "The Ad" out of "Advertising" when matching Web users to relevant things :-)
|
09/25/2008 20:42 GMT-0500
|
Modified:
09/26/2008 12:36 GMT-0500
|
|
|