I just found this interesting Semantic Web effort
via '
Danny Ayers' blog. Here
is the synopsis from his post:
Piggy
Bank 2.0 Beta
New release of Piggy
Bank, the Semantic Web extension for Firefox. It harvests data
as you browse (when you click a status bar indicator), which can
later be searched and viewed in a facetted browser.
The docs have come along some too -
Piggy Bank can collect pure information in the following
cases:
1. The web page has invisible link(s) to RDF data (encoded in
RDF/XML or N3 formats).
2. The web page exports an RSS feeds.
3. The address of the web page is a file:/ URL pointing to a
directory.
4. Piggy Bank has a "screen scraper" [XSLT or
Javascript] that can re-structure the web page HTML code into
RDF data.
There's a tutorial
on writing Javascript screenscrapers on the site, nice touch.
I have also added an architecture diagram
to accelerate comprehension (a picture speaks a thousand
words...):
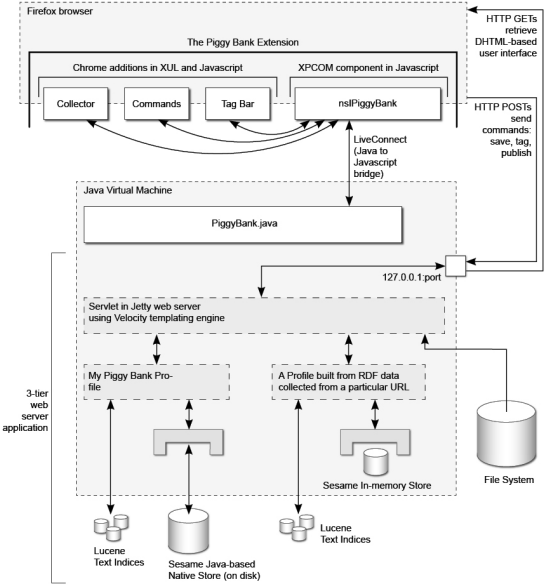
The infrastructure for tier-3 is an aspect of
Virtuoso's
functionality pool; combining Database & Web Application Server
functionality amongst other things, as a single product
offering.