One possible reason why organizations have still not wholly deployed XML, in spite of its versatility, across an organisation, can be attributed to their existing internal infrastructures, in particular legacy databases. A vast amount of business data is still stored within expensively assembled relational databases. The demand for these systems is sill high, howeverthe question of how to represent this data, taking advantage of XML so that it can be consumed by various clients is still proving a headache for many. Furthermore, there is a growing need for disparate systems to exchange data at both a high and low level which makes the link between accessing content stored within relational databases a priority The way non traditional data (documents) is being produced in XML format puts relational data to shame. There are several methods that can be used to retrieve XML data from relational databases. This paper will discuss one such method. SQL-XML, or SQLX or its most recent incarnation, SQL/XML (for the purpose of this paper we will use SQLX) is a simple process of running SQL statements and retrieving the results in XML as opposed to the common method of ASCII data. This is made possible by the addition of SQL operators which when combined with normal SQL syntax produce the desired results. Figure 1 shows the five operators currently in operation:
Please refer to the Virtuoso Function Guide documentation for more information on these operators
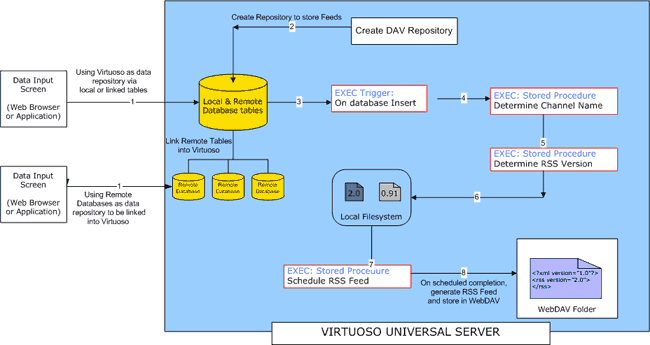
This system will be used to to insert a daily syndication of news and information to customers via RSS feeds. RSS feeds. (Really Simple Syndication.) Stage 1: Getting StartedIn Figure 2, shows a diagrammatic representation of the stages involved when generating our RSS feeds using SQLX: From the left of the diagram, we can follow the different stages involved from when we first insert our data via a web browser right through to the content been delivered as a RSS feed. The blue box represents the Virtuoso Server which can and hosts both the local and remote tables that contain our data
The first stage involves generating the content which will make up the RSS feed. This can be done in two ways. i. A feature of Virtuoso is its SQL-92 database. This means, it can host the content within its own database. ii. Alternatively, if the content already exists in a different location, i.e. a remote database. Using Virtuoso's Virtual database capabilities, it is possible to link in these tables from remote database (Oracle, SQLServer, DB2, MySQL, Postgres, Progress etc... using ODBC, JDBC or OLE-DB) Furthermore, the content from these tables does not have to be from a single remote source. It is possible to mix and match different database types simultaneously provided there is a common link between them. This is because, once linked into Virtuoso, they are seen as as local tables. For this project, we will be using the local Virtuoso tables created earlier. Stage 2: Creating the Results PageIn this stage we need to create the results page. The purpose of this page is to provide a template which will be the basis for the RSS feeds. As we're catering for two versions of RSS, v0.91 and v2.0, there will be two output pages. These pages will contain the SQLX functionality plus the logic required to produce the XML content. Using the Virtuoso PL as the basis, a breakdown of the code is as follows:
In Figure 3 we first add our XML declaration. This is always the first item in any XML document. We next declare our variables along with their datatypes. At this point we're adding Virtuoso PL logic(vsp) so this needs to be within a vsp section.
The http_header function is used to add additional HTTP header lines to the server response. In this context, as we are dealing with XML content, we give a content type of XML which the Virtuoso server will use as default. This also means Virtuoso WebDAV will identify the mime-type and be able to use the content in an appropriate way. We follow this by making some initial placeholder declarations. theserver: uses the soap function soap_current_url to get the full url of the current server. As the page may wellbe accessed from another virtual directory with another port number any hard-coded server and Port number address could be wrong. As a result we use this function to dynamically find the proper address. _chanid: provides the parameter used in our where clause in our SQL query. This value is derived from the parameter passed by rss_generate in its url String.
In the section we first check that a value has been passed to the _chanid variable. If not, a custom error is sent instead. If there is a value, we issue a select statement. This select statement contains our usual SQL but we have now added the SQLX operators. A breakdown of the SQL statement is as follows.
In Figure 5 we begin by declaring an error handler. This checks for the existence of a valid channel ID. If none exists, we return the error message “Channel Does not Exist”.
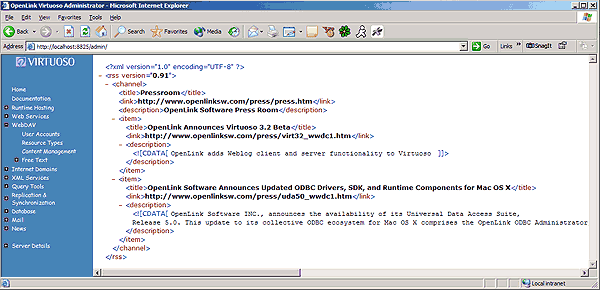
In our select statement, we issue an initial XMLELEMENT. This creates the root element with an alias of rss. We follow this with the XMLATTRIBUTES operator. The atributes of rss are version and namespace declaration. We have a manually created attribute of version with a default value of ‘2.0'. The same applies to our namespace declaration, xmlns:dc which also has a value of ‘ http://purl.org/dc/elements/1.1/'
In Figure 6 We add another XMLELEMENT operator. This will be nested wihin our existing element, RSS. This new element is called “channel” and has no attributes. The Channel data is derived from our channel table so to return its values we use the XMLFOREST operator. This is represented as a fragment, hence the use of the XMLFOREST operator. Again, we see the use of aliasing to create our RSS elements e.g… “chandesc” (table column name) will now be displayed as “description” in our XML document.
As we have more than one item in our table, as opposed to the Channel tag which should always return one record, we will combine all these item elements. This is made possible by the XMLAGG operator as we can see in Figure 7. Initially we add a nested XMLELEMENT, item, followed by a list of child elements which make up the item element. This is depicted by the XMLFOREST tag. We then enclose all this within the XMLAGG tag so we can combine them into one result. We also see an onother useful function in practice. soap_print_box is a Virtuoso function for converting database datetime values into a format RSS can use. We simply take the values of our item column, itempubdate, and whatever datetime values exist, Virtuoso will convert them into the correct format.
Finally, we alias the whole select statement into a variable called res. res will be used later when we output our results.
Finally, we provide some functionality which will enable us to display our results. There are two actions involved here. First, we need to write the output to a stream.
In Figure 8, we make use of some important Functions for outputtig results to a client in this case browser. With http_value (val_expr, tag, stream). The first parameter takes our SQLX statement, rss; our expected result will be in XML. We first write it to the stream _xml; What is written into this stream will be a serialization of the entire XML fragment as text including all the markup, i.e. elements, attributes, namespaces, text nodes, etc.
http takes an input parameter of string_output_stream, which in this case will be _xml.
Stage 3: Preparing the EngineOn completing our results templates pages, the next stage involves creating a storage area within Virtuoso. This will be done via Virtuoso's Content Management feature and will act as the staging area where all the feeds can be accessed. To create the WebDAV folders we execute the following:
This will create a folder called rssfeeds in the Virtuoso Server, e.g. http://localhost:8890/DAV/rssfeeds, with read permissions for all users. The real engine in this project are three stored Procedures and the event trigger. Please run the script file to create these procedures and triggers.
This procedure derives the name of the channel from the Channel table and replaces any spaces with an underscore. On completion, the name will be the name of the actual RSS feed. In Figure 10 this procedure rss_generate is used to select the correct XML template to be used. In this case, we will use the sqlx_rss20.vsp page we created. The logic in this code states that if the Channel ID is less than 2.0, we return, via the http_get function, the sqlx_rss91.vsp page, else we return the sqlx_rss20vsp page.
The name of the resultant RSS feed page is derived from the initial function, filename_of. The Virtuoso function DAV_RES_UPLOAD is then used to upload this file. We also check for the existence of the same scheduled event. If one exists, it is deleted from the list of scheduled events and replaced with this one .
In Figure11, our procedure schedule_rss creates an entry in the list of scheduled events in Virtuoso. By scheduling an event, we get Virtuoso to perform the automatic updates. These updates are scheduled at intervals of 10mins. For the schedule to occur, it requires an event to happen. This event will be a trigger.
The trigger, rss_generate occurs after every insert statement on the Item Table.
Stage 4: Testing the systemUsing the sample data provided in the zipattachment, we are ready to populate our system via the items.vsp page. On completion, we can check that the event we've scheduled, via our Stored Procedures and triggers, has infact been scheduled. This is done by issuing the following SQL statement below. select * from db.dba.SYS_SCHEDULED_EVENT As shown in Figure 13, the results will show in a list of scheduled events. On a successful execution of the event, a timestamp will be added to the table indicating when it was last run.
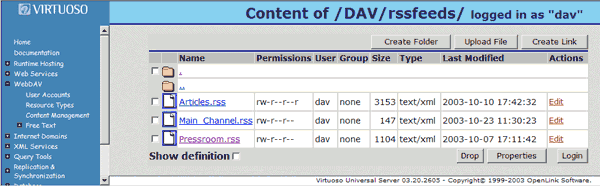
On completion, the RSS file will be stored within WebDAV (Content Management). From the Admin Assistant: Figure 14 Administration -> WebDAV -> Content Management
Conclusion:
With our RSS feed complete, we've not only shown one method in retrieving XML data and converting it to XML, we' have also shown the versatility of Virtuoso. So far, we' have explored Virtuoso's Database capabilities for hosting tables, HTTP server for hosting Web Content, WebDAV for Content Management, Event Scheduler for scheduling our RSS feed executions. Along the way we also looked at Virtuoso's PL langage , VSP, plus its Stored Procedure and Trigger support.
As the content is stored within a WebDAV folder, it is now accessible over the internet, provided the machine is accessible on the internet. As Virtuoso has its own Web Server, a domain can be registered to display the results. Alternatively, the same file can be added to an existing webserver. To reference this page, so News Aggregators can access this feed, we simply provide a link within our webpage, similar to:
<link rel="relatedLink" title="RSS" href="http://localhost:8890/DAV/rssfeeds/pressroom-rss.xml" />
Alternatively, if we had stylesheets (.css), we could use the Virtuoso XSLT engine to transform this XML file into a different format. A virtuoso function exists for this task. In the next paper, we will look at another method of retrieving RSS. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||






{kind=link}
{kind=link}
{kind=link}