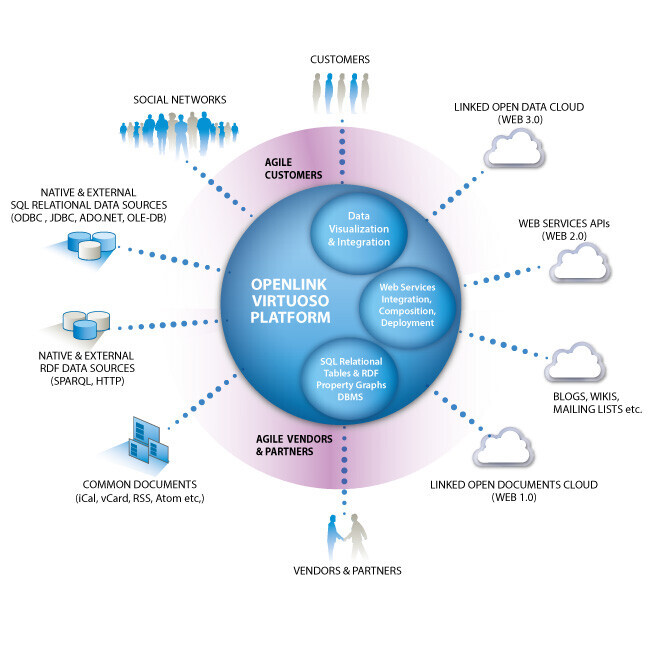
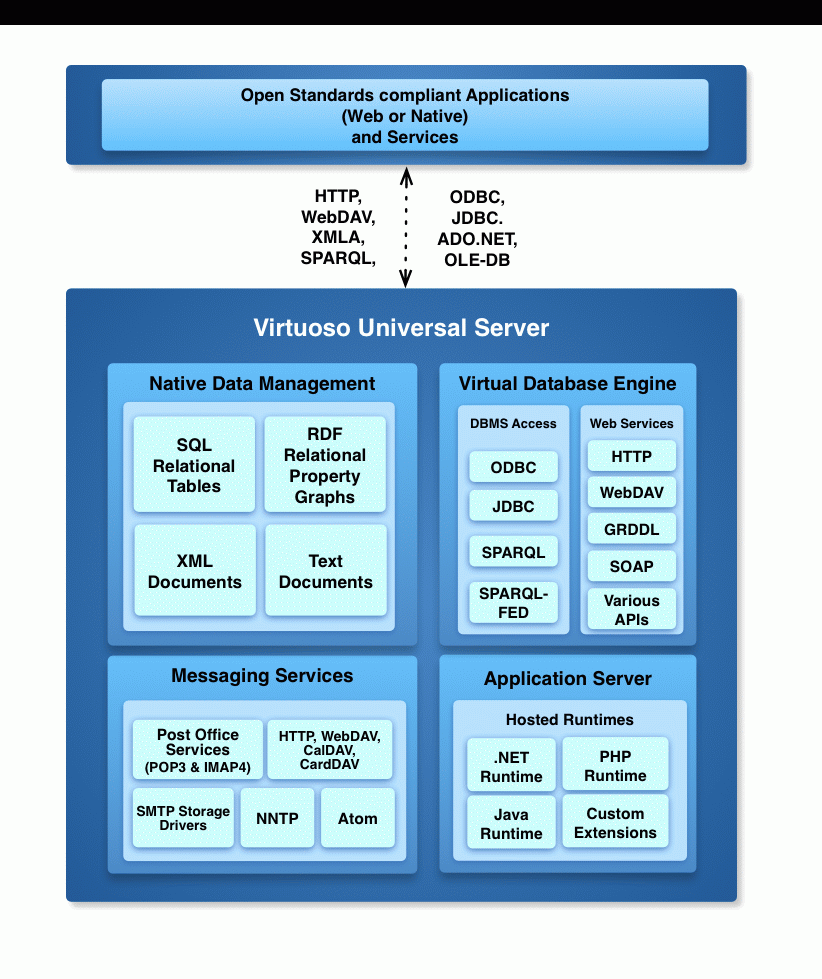
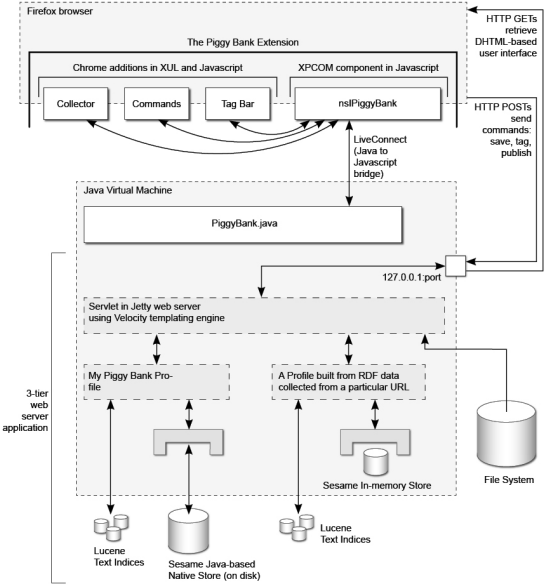
Editorial Note: Several months ago, AlwaysOn got a personal invitation from Yahoo founder Jerry Yang "to see and give us feedback on our new social media product, y!360." We were happy to oblige and dutifully showed up, joining a conference room full of hard-core bloggers and new, new media types. The geeks gave Yahoo 360 an overwhelming thumbs down, with comments like, "So the only services I can use within this new network are Yahoo services? What if I don't use Yahoo IM?" In essence, the Yahoo team was booed for being "closed web," and we heartily agreed. With Yahoo 360, Yahoo continues building its own "walled garden" to control its 135 million customersÂan accusation also hurled at AOL in the early 1990s, before AOL migrated its private network service onto the web. As the Economist recently noted, "Yahoo, in short, has old media plans for the new-media era." Editorial Note: Several months ago, AlwaysOn got a personal invitation from Yahoo founder Jerry Yang "to see and give us feedback on our new social media product, y!360." We were happy to oblige and dutifully showed up, joining a conference room full of hard-core bloggers and new, new media types. The geeks gave Yahoo 360 an overwhelming thumbs down, with comments like, "So the only services I can use within this new network are Yahoo services? What if I don't use Yahoo IM?" In essence, the Yahoo team was booed for being "closed web," and we heartily agreed. With Yahoo 360, Yahoo continues building its own "walled garden" to control its 135 million customersÂan accusation also hurled at AOL in the early 1990s, before AOL migrated its private network service onto the web. As the Economist recently noted, "Yahoo, in short, has old media plans for the new-media era."
The irony to our view here is, of course, that today's AO Network is also a "closed web." In the end, Mr. Yang's thoughtful invitation and our ensuing disappointment in his new service led to the assignment of this article. It also confirmed our existing plan to completely revamp the AO Network around open standards. To tie it all together, we recruited the chief architect of our new site, the notorious Marc Canter, to pen this piece. We look forward to our reader feedback.
Breaking the Web Wide Open!
By Marc Canter
For decades, "walled gardens" of proprietary standards and content have been the strategy of dominant players in mainframe computer software, wireless telecommunications services, and the World Wide WebÂit was their successful lock-in strategy of keeping their customers theirs. But like it or not, those walls are tumbling down. Open web standards are being adopted so widely, with such value and impact, that the web giantsÂAmazon, AOL, eBay, Google, Microsoft, and YahooÂare facing the difficult decision of opening up to what they don't control.
The online world is evolving into a new open web (sometimes called the Web 2.0), which is all about being personalized and customized for each user. Not only open source software, but open standards are becoming an essential component.
Many of the web giants have been using open source software for years. Most of them use at least parts of the LAMP (Linux, Apache, MySQL, Perl/Python/PHP) stack, even if they aren't well-known for giving back to the open source community. For these incumbents that grew big on proprietary web services, the methods, practices, and applications of open source software development are difficult to fully adopt. And the next open source movementsÂwhich will be as much about open standards as about codeÂwill be a lot harder for the incumbents to exploit.
While the incumbents use cheap open source software to run their back-ends systems, their business models largely depend on proprietary software and algorithms. But our view a new slew of open software, open protocols, and open standards will confront the incumbents with the classic Innovator's Dilemma. Should they adopt these tools and standards, painfully cannibalizing their existing revenue for a new unproven concept, or should they stick with their currently lucrative model with the risk that eventually a bunch of upstarts eat their lunch?
Credit should go to several of the web giants who have been making efforts to "open up." Google, Yahoo, eBay, and Amazon all have Open APIs (Application Programming Interfaces) built into their data and systems. Any software developer can access and use them for whatever creative purposes they wish. This means that the API provider becomes an open platform for everyone to use and build on top of. This notion has expanded like wildfire throughout the blogosphere, so nowadays, Open APIs are pretty much required.
Other incumbents also have open strategies. AOL has got the RSS religion, providing a feedreader and RSS search in order to escape the "walled garden of content" stigma. Apple now incorporates podcasts, the "personal radio shows" that are latest rage in audio narrowcasting, into iTunes. Even Microsoft is supporting open standards, for example by endorsing SIP (Session Initiation Protocol) for internet telephony and conferencing over Skype's proprietary format or one of its own devising.
But new open standards and protocols are in use, under construction, or being proposed every day, pushing the envelope of where we are right now. Many of these standards are coming from startup companies and small groups of developers, not from the giants. Together with the Open APIs, those new standards will contribute to a new, open infrastructure. Tens of thousands of developers will use and improve this open infrastructure to create new kinds of web-based applications and services, to offer web users a highly personalized online experience.
A Brief History of Openness
At this point, I have to admit that I am not just a passive observer, full-time journalist or "just some blogger"Âbut an active evangelist and developer of these standards. It's the vision of "open infrastructure" that's driving my company and the reason why I'm writing this article. This article will give you some of the background behind on these standards, and what the evolution of the next generation of open standards will look like.
Starting back in the 1980s, establishing a software standard was a key strategy for any software company. My former company, MacroMind (which became Macromedia), achieved this goal early on with Director. As Director evolved into Flash, the world saw that other companies besides Microsoft, Adobe, and Apple could establish true cross-platform, independent media standards.
Then Tim Berners-Lee and Marc Andreessen came along, and changed the rules of the software business and of entrepreneurialism. No matter how entrenched and "standardized" software was, the rug could still get pulled out from under it. Netscape did it to Microsoft, and then Microsoft did it back to Netscape. The web evolved, and lots of standards evolved with it. The leading open source standards (such as the LAMP stack) became widely used alternatives to proprietary closed-source offerings.
Open standards are more than just technology. Open standards mean sharing, empowering, and community support. Someone floats a new idea (or meme) and the community runs with it â with each person making their own contributions to the standard â evolving it without a moment's hesitation about "giving away their intellectual property."
One good example of this was Dave Sifry, who built the Technorati blog-tracking technology inspired by the Blogging Ecosystem, a weekend project by young hacker Phil Pearson. Dave liked what he saw and he ran with itÂturning Technorati into what it is today.
Dave Winer has contributed enormously to this area of open standards. He defined and personally created several open standards and protocolsÂsuch as RSS, OPML, and XML-RPC. Dave has also helped build the blogosphere through his enthusiasm and passion.
By 2003, hundreds of programmers were working on creating and establishing new standards for almost everything. The best of these new standards have evolved into compelling web services platforms â such as del.icio.us, Webjay, or Flickr. Some have even spun off formal standards â like XSPF (a standard for playlists) or instant messaging standard XMPP (also known as Jabber).
Today's Open APIs are complemented by standardized SchemasÂthe structure of the data itself and its associated meta-data. Take for example a podcasting feed. It consists of: a) the radio show itself, b) information on who is on the show, what the show is about and how long the show is (the meta-data) and also c) API calls to retrieve a show (a single feed item) and play it from a specified server.
The combination of Open APIs, standardized schemas for handling meta-data, and an industry which agrees on these standards are breaking the web wide open right now. So what new open standards should the web incumbentsÂand youÂbe watching? Keep an eye on the following developments:
Identity
Attention
Open Media
Microcontent Publishing
Open Social Networks
Tags
Pinging
Routing
Open Communications
Device Management and Control
1. Identity
Right now, you don't really control your own online identity. At the core of just about every online piece of software is a membership system. Some systems allow you to browse a site anonymouslyÂbut unless you register with the site you can't do things like search for an article, post a comment, buy something, or review it. The problem is that each and every site has its own membership system. So you constantly have to register with new systems, which cannot share dataÂeven you'd want them to. By establishing a "single sign-on" standard, disparate sites can allow users to freely move from site to site, and let them control the movement of their personal profile data, as well as any other data they've created.
With Passport, Microsoft unsuccessfully attempted to force its proprietary standard on the industry. Instead, a world is evolving where most people assume that users want to control their own data, whether that data is their profile, their blog posts and photos, or some collection of their past interactions, purchases, and recommendations. As long as users can control their digital identity, any kind of service or interaction can be layered on top of it.
Identity 2.0 is all about users controlling their own profile data and becoming their own agents. This way the users themselves, rather than other intermediaries, will profit from their ID info. Once developers start offering single sign-on to their users, and users have trusted places to store their dataÂwhich respect the limits and provide access controls over that data, users will be able to access personalized services which will understand and use their personal data.
Identity 2.0 may seem like some geeky, visionary future standard that isn't defined yet, but by putting each user's digital identity at the core of all their online experiences, Identity 2.0 is becoming the cornerstone of the new open web.
The Initiatives:
Right now, Identity 2.0 is under construction through various efforts from Microsoft (the "InfoCard" component built into the Vista operating system and its "Identity Metasystem"), Sxip Identity, Identity Commons, Liberty Alliance, LID (NetMesh's Lightweight ID), and SixApart's OpenID.
More Movers and Shakers:
Identity Commons and Kaliya Hamlin, Sxip Identity and Dick Hardt, the Identity Gang and Doc Searls, Microsoft's Kim Cameron, Craig Burton, Phil Windley, and Brad Fitzpatrick, to name a few.
2. Attention
How many readers know what their online attention is worth? If you don't, Google and Yahoo doÂthey make their living off our attention. They know what we're searching for, happily turn it into a keyword, and sell that keyword to advertisers. They make money off our attention. We don't.
Technorati and friends proposed an attention standard, Attention.xml, designed to "help you keep track of what you've read, what you're spending time on, and what you should be paying attention to." AttentionTrust is an effort by Steve Gillmor and Seth Goldstein to standardize on how captured end-user performance, browsing, and interest data are used.
Blogger Peter Caputa gives a good summary of AttentionTrust: "As we use the web, we reveal lots of information about ourselves by what we pay attention to. Imagine if all of that information could be stored in a nice neat little xml file. And when we travel around the web, we can optionally share it with websites or other people. We can make them pay for it, lease it ... we get to decide who has access to it, how long they have access to it, and what we want in return. And they have to tell us what they are going to do with our Attention data."
So when you give your attention to sites that adhere to the AttentionTrust, your attention rights (you own your attention, you can move your attention, you can pay attention and be paid for it, and you can see how your attention is used) are guaranteed. Attention data is crucial to the future of the open web, and Steve and Seth are making sure that no one entity or oligopoly controls it.
Movers and Shakers:
Steve Gillmor, Seth Goldstein, Dave Sifry and the other Attention.xml folks.
3. Open Media
Proprietary media standardsÂFlash, Windows Media, and QuickTime, to name a few Âhelped liven up the web. But they are proprietary standards that try to keep us locked in, and they weren't created from scratch to handle today's online content. That's why, for many of us, an Open Media standard has been a holy grail. Yahoo's new Media RSS standard brings us one step closer to achieving open media, as do Ogg Vorbis audio codecs, XSPF playlists, or MusicBrainz. And several sites offer digital creators not only a place to store their content, but also to sell it.
Media RSS (being developed by Yahoo with help from the community) extends RSS and combines it with "RSS enclosures" Âadds metadata to any media itemÂto create a comprehensive solution for media "narrowcasters." To gain acceptance for Media RSS, Yahoo knows it has to work with the community. As an active member of this community, I can tell you that we'll create Media RSS equivalents for rdf (an alternative subscription format) and Atom (yet another subscription format), so no one will be able to complain that Yahoo is picking sides in format wars.
When Yahoo announced the purchase of Flickr, Yahoo founder Jerry Yang insinuated that Yahoo is acquiring "open DNA" to turn Yahoo into an open standards player. Yahoo is showing what happens when you take a multi-billion dollar company and make openness one of its core valuesÂso Google, beware, even if Google does have more research fellows and Ph.D.s.
The open media landscape is far and wide, reaching from game machine hacks and mobile phone downloads to PC-driven bookmarklets, players, and editors, and it includes many other standardization efforts. XSPF is an open standard for playlists, and MusicBrainz is an alternative to the proprietary (and originally effectively stolen) database that Gracenote licenses.
Ourmedia.org is a community front-end to Brewster Kahle's Internet Archive. Brewster has promised free bandwidth and free storage forever to any content creators who choose to share their content via the Internet Archive. Ourmedia.org is providing an easy-to-use interface and community to get content in and out of the Internet Archive, giving ourmedia.org users the ability to share their media anywhere they wish, without being locked into a particular service or tool. Ourmedia plans to offer open APIs and an open media registry that interconnects other open media repositories into a DNS-like registry (just like the www domain system), so folks can browse and discover open content across many open media services. Systems like Brightcove and Odeo support the concept of an open registry, and hope to work with digital creators to sell their work to fulfill the financial aspect of the "Long Tail."
More Movers and Shakers:
Creative Commons, the Open Media Network, Jay Dedman, Ryanne Hodson, Michael Verdi, Eli Chapman, Kenyatta Cheese, Doug Kaye, Brad Horowitz, Lucas Gonze, Robert Kaye, Christopher Allen, Brewster Kahle, JD Lasica, and indeed, Marc Canter, among others.
4. Microcontent Publishing
Unstructured content is cheap to create, but hard to search through. Structured content is expensive to create, but easy to search. Microformats resolve the dilemma with simple structures that are cheap to use and easy to search.
The first kind of widely adopted microcontent is blogging. Every post is an encapsulated idea, addressable via a URL called a permalink. You can syndicate or subscribe to this microcontent using RSS or an RSS equivalent, and news or blog aggregators can then display these feeds in a convenient readable fashion. But a blog post is just a block of unstructured textânot a bad thing, but just a first step for microcontent. When it comes tostructured data, such as personal identity profiles, product reviews, or calendar-type event data, RSS was not designed to maintain the integrity of the structures.
Right now, blogging doesn't have the underlying structure necessary for full-fledged microcontent publishing. But that will change. Think of local information services (such as movie listings, event guides, or restaurant reviews) that any college kid can access and use in her weekend programming project to create new services and tools.
Today's blogging tools will evolve into microcontent publishing systems, and will help spread the notion of structured data across the blogosphere. New ways to store, represent and produce microcontent will create new standards, such as Structured Blogging and Microformats. Microformats differ from RSS feeds in that you can't subscribe to them. Instead, Microformats are embedded into webpages and discovered by search engines like Google or Technorati. Microformats are creating common definitions for "What is a review or event? What are the specific fields in the data structure?" They can also specify what we can do with all this information.OPML (Outline Processor Markup Language) is a hierarchical file format for storing microcontent and structured data. It was developed by Dave Winer of RSS and podcast fame.
Events are one popular type of microcontent. OpenEvents is already working to create shared databases of standardized events, which would get used by a new generation of event portalsâsuch as Eventful/EVDB, Upcoming.org, and WhizSpark. The idea of OpenEvents is that event-oriented systems and services can work together to establish shared events databases (and associated APIs) that any developer could then use to create and offer their own new service or application. OpenReviews is still in the conceptual stage, but it would make it possible to provide open alternatives to closed systems like Epinions, and establish a shared database of local and global reviews. Its shared open servers would be filled with all sorts of reviews for anyone to access.
Why is this important? Because I predict that in the future, 10 times more people will be writing reviews than maintaining their own blog. The list of possible microcontent standards goes on: OpenJobpostings, OpenRecipes, and even OpenLists. Microsoft recently revealed that it has been working on an important new kind of microcontent: Listsâso OpenLists will attempt to establish standards for the kind of lists we all use, such as lists of Links, lists of To Do Items, lists of People, Wish Lists, etc.
Movers and Shakers:
Tantek Ãelik and Kevin Marks of Technorati, Danny Ayers, Eric Meyer, Matt Mullenweg, Rohit Khare, Adam Rifkin, Arnaud Leene, Seb Paquet, Alf Eaton, Phil Pearson, Joe Reger, Bob Wyman among others.
5. Open Social Networks
I'll never forget the first time I met Jonathan Abrams, the founder of Friendster. He was arrogant and brash and he claimed he "owned"Â all his users, and that he was going to monetize them and make a fortune off them. This attitude robbed Friendster of its momentum, letting MySpace, Facebook, and other social networks take Friendster's place.
Jonathan's notion of social networks as a way to control users is typical of the Web 1.0 business model and its attitude towards users in general. Social networks have become one of the battlegrounds between old and new ways of thinking. Open standards for Social Networking will define those sides very clearly. Since meeting Jonathan, I have been working towards finding and establishing open standards for social networks. Instead of closed, centralized social networks with 10 million people in them, the goal is making it possible to have 10 million social networks that each have 10 people in them.
FOAF (which stands for Friend Of A Friend, and describes people and relationships in a way that computers can parse) is a schema to represent not only your personal profile's meta-data, but your social network as well. Thousands of researchers use the FOAF schema in their "Semantic Web" projects to connect people in all sorts of new ways. XFN is a microformat standard for representing your social network, while vCard (long familiar to users of contact manager programs like Outlook) is a microformat that contains your profile information. Microformats are baked into any xHTML webpage, which means thatany blog, social network page, or any webpage in general can "contain" your social network in itÂand be used byany compatible tool, service or application.
PeopleAggregator is an earlier project now being integrated into open content management framework Drupal. The PeopleAggregator APIs will make it possible to establish relationships, send messages, create or join groups, and post between different social networks. (Sneak preview: this technology will be available in the upcoming GoingOn Network.)
All of these open social networking standards mean that inter-connected social networks will form a mesh that will parallel the blogosphere. This vibrant, distributed, decentralized world will be driven by open standards: personalized online experiences are what the new open web will be all aboutÂand what could be more personalized than people's networks?
Movers and Shakers:
Eric Sigler, Joel De Gan, Chris Schmidt, Julian Bond, Paul Martino, Mary Hodder, Drummond Reed, Dan Brickley, Randy Farmer, and Kaliya Hamlin, to name a few.
6. Tags
Nowadays, no self-respecting tool or service can ship without tags. Tags are keywords or phrases attached to photos, blog posts, URLs, or even video clips. These user- and creator-generated tags are an open alternative to what used to be the domain of librarians and information scientists: categorizing information and content using taxonomies. Tags are instead creating "folksonomies."
The recently proposed OpenTags concept would be an open, community-owned version of the popular Technorati Tags service. It would aggregate the usage of tags across a wide range of services, sites, and content tools. In addition to Technorati's current tag features, OpenTags would let groups of people share their tags in "TagClouds." Open tagging is likely to include some of the open identity features discussed above, to create a tag system that is resilient to spam, and yet trustable across sites all over the web.
OpenTags owes a debt to earlier versions of shared tagging systems, which include Topic Exchange and something called the k-collectorÂa knowledge management tag aggregatorÂfrom Italian company eVectors.
Movers & Shakers:
Phil Pearson, Matt Mower , Paolo Valdemarin, and Mary Hodder and Drummond Reed again, among others.
7. Pinging
Websites used to be mostly static. Search engines that crawled (or "spidered") them every so often did a good enough job to show reasonably current versions of your cousin's homepage or even Time magazine's weekly headlines. But when blogging took off, it became hard for search engines to keep up. (Google has only just managed to offer blog-search functionality, despite buying Blogger back in early 2003.)
To know what was new in the blogosphere, users couldn't depend on services that spidered webpages once in a while. The solution: a way for blogs themselves to automatically notify blog-tracking sites that they'd been updated. Weblogs.com was the first blog "ping service": it displayed the name of a blog whenever that blog was updated. Pinging sites helped the blogosphere grow, and more tools, services, and portals started using pinging in new and different ways. Dozens of pinging services and sitesÂmost of which can't talk to each otherÂsprang up.
Matt Mullenweg (the creator of open source blogging software WordPress) decided that a one-stop service for pinging was needed. He created Ping-o-MaticÂwhich aggregates ping services and simplifies the pinging process for bloggers and tool developers. With Ping-o-Matic, any developer can alert all of the industry's blogging tools and tracking sites at once. This new kind of open standard, with shared infrastructure, is a critical to the scalability of Web 2.0 services.
As Matt said:
There are a number of services designed specifically for tracking and connecting blogs. However it would be expensive for all the services to crawl all the blogs in the world all the time. By sending a small ping to each service you let them know you've updated so they can come check you out. They get the freshest data possible, you don't get a thousand robots spidering your site all the time. Everybody wins.
Movers and Shakers:
Matt Mullenweg, Jim Winstead, Dave Winer
8. Routing
Bloggers used to have to manually enter the links and content snippets of blog posts or news items they wanted to blog. Today, some RSS aggregators can send a specified post directly into an associated blogging tool: as bloggers browse through the feeds they subscribe to, they can easily specify and send any post they wish to "reblog" from their news aggregator or feed reader into their blogging tool. (This is usually referred to as "BlogThis.") As structured blogging comes into its own (see the section on Microcontent Publishing), it will be increasingly important to maintain the structural integrity of these pieces of microcontent when reblogging them.
Promising standard RedirectThis will combine a "BlogThis"-like capability while maintaining the integrity of the microcontent. RedirectThis will let bloggers and content developers attach a simple "PostThis" button to their posts. Clicking on that button will send that post to the reader/blogger's favorite blogging tool. This favorite tool is specified at the RedirectThis web service, where users register their blogging tool of choice. RedirectThis also helps maintain the integrity and structure of microcontentÂthen it's just up to the user to prefer a blogging tool that also attains that lofty goal of microcontent integrity.
OutputThis is another nascent web services standard, to let bloggers specify what "destinations" they'd like to have as options in their blogging tool. As new destinations are added to the service, more checkboxes would get added to their blogging toolÂallowing them to route their published microcontent to additional destinations.
Movers and Shakers:
Michael Migurski, Lucas Gonze
9. Open Communications
Likely, you've experienced the joys of finding friends on AIM or Yahoo Messenger, or the convenience of Skyping with someone overseas. Not that you're about to throw away your mobile phone or BlackBerry, but for many, also having access to Instant Messaging (IM) and Voice over IP (VoIP) is crucial.
IM and VoIP are mainstream technologies that already enjoy the benefits of open standards. Entire industries are bornÂright this secondÂbased around these open standards. Jabber has been an open IM technology for yearsÂin fact, as XMPP, it was officially dubbed a standard by the IETF. Although becoming an official IETF standard is usually the kiss of death, Jabber looks like it'll be around for a while, as entire generations of collaborative, work-group applications and services have been built on top of its messaging protocol. For VoIP, Skype is clearly the leading standard todayÂthough one could argue just how "open" it is (and defenders of the IETF's SIP standard often do). But it is free and user-friendly, so there won't be much argument from users about it being insufficiently open. Yet there may be a cloud on Skype's horizon: web behemoth Google recently released a beta of Google Talk, an IM client committed to open standards. It currently supports XMPP, and will support SIP for VoIP calls.
Movers and Shakers:
Jeremie Miller, Henning Schulzrinne, Jon Peterson, Jeff Pulver
10. Device Management and Control
To access online content, we're using more and more devices. BlackBerrys, iPods, Treos, you name it. As the web evolves, more and more different devices will have to communicate with each other to give us the content we want when and where we want it. No-one wants to be dependent on one vendor anymoreÂlike, say, SonyÂfor their laptop, phone, MP3 player, PDA, and digital camera, so that it all works together. We need fully interoperable devices, and the standards to make that work. And to fully make use of how content is moving online content and innovative web services, those standards need to be open.
MIDI (musical instrument digital interface), one of the very first open standards in music, connected disparate vendors' instruments, post-production equipment, and recording devices. But MIDI is limited, and MIDI II has been very slow to arrive. Now a new standard for controlling musical devices has emerged: OSC (Open SoundControl). This protocol is optimized for modern networking technology and inter-connects music, video and controller devices with "other multimedia devices." OSC is used by a wide range of developers, and is being taken up in the mainstream MIDI marketplace.
Another open-standards-based device management technology is ZigBee, for building wireless intelligence and network monitoring into all kinds of devices. ZigBee is supported by many networking, consumer electronics, and mobile device companies.
   · · · · · ·  Â
The Change to Openness
The rise of open source software and its "architecture of participation" are completely shaking up the old proprietary-web-services-and-standards approach. Sun MicrosystemsÂwhose proprietary Java standard helped define the Web 1.0Âis opening its Solaris OS and has even announced the apparent paradox of an open-source Digital Rights Management system.
Today's incumbents will have to adapt to the new openness of the Web 2.0. If they stick to their proprietary standards, code, and content, they'll become the new walled gardensÂplaces users visit briefly to retrieve data and content from enclosed data silos, but not where users "live." The incumbents' revenue models will have to change. Instead of "owning" their users, users will know they own themselves, and will expect a return on their valuable identity and attention. Instead of being locked into incompatible media formats, users will expect easy access to digital content across many platforms.
Yesterday's web giants and tomorrow's users will need to find a mutually beneficial new balanceÂbetween open and proprietary, developer and user, hierarchical and horizontal, owned and shared, and compatible and closed.
Marc Canter is an active evangelist and developer of open standards. Early in his career, Marc founded MacroMind, which became Macromedia. These days, he is CEO of Broadband Mechanics, a founding member of the Identity Gang and of ourmedia.org. Broadband Mechanics is currently developing the GoingOn Network (with the AlwaysOn Network), as well as an open platform for social networking called the PeopleAggregator.
A version of the above post appears in the Fall 2005 issue of AlwaysOn's quarterly print blogozine, and ran as a four-part series on the AlwaysOn Network website. |