What is the Data Access, and Data Management Value Pyramid?
As depicted below, a top-down view of the data access and data management value chain. The term: apex, simply indicates value primacy, which takes the form of a data access API based entry point into a DBMS realm -- aligned to an underlying data model. Examples of data access APIs include: Native Call Level Interfaces (CLIs), ODBC, JDBC, ADO.NET, OLE-DB, XMLA, and Web Services.

The degree to which ad-hoc views of data managed by a DBMS can be produced and dispatched to relevant data consumers (e.g. people), without compromising concurrency, data durability, and security, collectively determine the "Agility Value Factor" (AVF) of a given DBMS. Remember, agility as the cornerstone of environmental adaptation is as old as the concept of evolution, and intrinsic to all pursuits of primacy.
In simpler business oriented terms, look at AVF as the degree to which DBMS technology affects the ability to effectively implement "Market Leadership Discipline" along the following pathways: innovation, operation excellence, or customer intimacy.
Why has RDBMS Primacy has Endured?
Historically, at least since the late '80s, the RDBMS genre of DBMS has consistently offered the highest AVF relative to other DBMS genres en route to primacy within the value pyramid. The desire to improve on paper reports and spreadsheets is basically what DBMS technology has fundamentally addressed to date, even though conceptual level interaction with data has never been its forte.

For more then 10 years -- at the very least -- limitations of the traditional RDBMS in the realm of conceptual level interaction with data across diverse data sources and schemas (enterprise, Web, and Internet) has been crystal clear to many RDBMS technology practitioners, as indicated by some of the quotes excerpted below:
"Future of Database Research is excellent, but what is the future of data?"
"..it is hard for me to disagree with the conclusions in this report. It captures exactly the right thoughts, and should be a must read for everyone involved in the area of databases and database research in particular."-- Dr. Anant Jingran, CTO, IBM Information Management Systems, commenting on the 2007 RDBMS technology retreat attended by a number of key DBMS technology pioneers and researchers.
"One size fits all: A concept whose time has come and gone
- They are direct descendants of System R and Ingres and were architected more than 25 years ago
- They are advocating "one size fits all"; i.e. a single engine that solves all DBMS needs.
-- Prof. Michael Stonebreaker, one of the founding fathers of the RDBMS industry.
Until this point in time, the requisite confluence of "circumstantial pain" and "open standards" based technology required to enable an objective "compare and contrast" of RDBMS engine virtues and viable alternatives hasn't occurred. Thus, the RDBMS has endured it position of primacy albeit on a "one size fits all basis".
Circumstantial Pain
As mentioned earlier, we are in the midst of an economic crisis that is ultimately about a consistent inability to connect dots across a substrate of interlinked data sources that transcend traditional data access boundaries with high doses of schematic heterogeneity. Ironically, in a era of the dot-com, we haven't been able to make meaningful connections between relevant "real-world things" that extend beyond primitive data hosted database tables and content management style document containers; we've struggled to achieve this in the most basic sense, let alone evolve our ability to connect inline with the exponential rate at which the Internet & Web are spawning "universes of discourse" (data spaces) that emanate from user activity (within the enterprise and across the Internet & Web). In a nutshell, we haven't been able to upgrade our interaction with data such that "conceptual models" and resulting "context lenses" (or facets) become concrete; by this I mean: real-world entity interaction making its way into the computer realm as opposed to the impedance we all suffer today when we transition from conceptual model interaction (real-world) to logical model interaction (when dealing with RDBMS based data access and data management).
Here are some simple examples of what I can only best describe as: "critical dots unconnected", resulting from an inability to interact with data conceptually:
Government (Globally) -Financial regulatory bodies couldn't effectively discern that a Credit Default Swap is an Insurance policy in all but literal name. And in not doing so the cost of an unregulated insurance policy laid the foundation for exacerbating the toxicity of fatally flawed mortgage backed securities. Put simply: a flawed insurance policy was the fallback on a toxic security that financiers found exotic based on superficial packaging.
Enterprises -Banks still don't understand that capital really does exists in tangible and intangible forms; with the intangible being the variant that is inherently dynamic. For example, a tech companies intellectual capital far exceeds the value of fixture, fittings, and buildings, but you be amazed to find that in most cases this vital asset has not significant value when banks get down to the nitty gritty of debt collateral; instead, a buffer of flawed securitization has occurred atop a borderline static asset class covering the aforementioned buildings, fixtures, and fittings.
In the general enterprise arena, IT executives continued to "rip and replace" existing technology without ever effectively addressing the timeless inability to connect data across disparate data silos generated by internal enterprise applications, let alone the broader need to mesh data from the inside with external data sources. No correlations made between the growth of buzzwords and the compounding nature of data integration challenges. It's 2009 and only a miniscule number of executives dare fantasize about being anywhere within distance of the: relevant information at your fingertips vision.
Looking more holistically at data interaction in general, whether you interact with data in the enterprise space (i.e., at work) or on the Internet or Web, you ultimately are delving into a mishmash of disparate computer systems, applications, service (Web or SOA), and databases (of the RDBMS variety in a majority of cases) associated with a plethora of disparate schemas. Yes, but even today "rip and replace" is still the norm pushed by most vendors; pitting one mono culture against another as exemplified by irrelevances such as: FOSS/LAMP vs Commercial or Web vs. Enterprise, when none of this matters if the data access and integration issues are recognized let alone addressed (see: Applications are Like Fish and Data Like Wine).
Like the current credit-crunch, exponential growth of data originating from disparate application databases and associated schemas, within shrinking processing time frames, has triggered a rethinking of what defines data access and data management value today en route to an inevitable RDBMS downgrade within the value pyramid.
Technology
There have been many attempts to address real-world modeling requirements across the broader DBMS community from Object Databases to Object-Relational Databases, and more recently the emergence of simple Entity-Attribute-Value model DBMS engines. In all cases failure has come down to the existence of one or more of the following deficiencies, across each potential alternative:
- Query language standardization - nothing close to SQL standardization
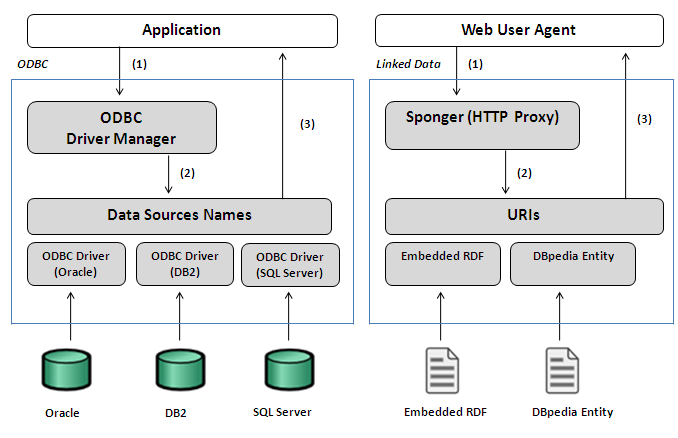
- Data Access API standardization - nothing close to ODBC, JDBC, OLE-DB, or ADO.NET
- Wire protocol standardization - nothing close to HTTP
- Distributed Identity infrastructure - nothing close to the non-repudiatable digital Identity that foaf+ssl accords
- Use of Identifiers as network based pointers to data sources - nothing close to RDF based Linked Data
- Negotiable data representation - nothing close to Mime and HTTP based Content Negotiation
- Scalability especially in the era of Internet & Web scale.
Entity-Attribute-Value with Classes & Relationships (EAV/CR) data models
A common characteristic shared by all post-relational DBMS management systems (from Object Relational to pure Object) is an orientation towards variations of EAV/CR based data models. Unfortunately, all efforts in the EAV/CR realm have typically suffered from at least one of the deficiencies listed above. In addition, the same "one DBMS model fits all" approach that lies at the heart of the RDBMS downgrade also exists in the EAV/CR realm.
What Comes Next?
The RDBMS is not going away (ever), but its era of primacy -- by virtue of its placement at the apex of the data access and data management value pyramid -- is over! I make this bold claim for the following reasons:
- The Internet aided "Global Village" has brought "Open World" vs "Closed World" assumption issues to the fore e.g., the current global economic crisis remains centered on the inability to connect dots across "Open World" and "Closed World" data frontiers
- Entity-Attribute-Value with Classes & Relationships (EAV/CR) based DBMS models are more effective when dealing with disparate data associated with disparate schemas, across disparate DBMS engines, host operating systems, and networks.
Based on the above, it is crystal clear that a different kind of DBMS -- one with higher AVF relative to the RDBMS -- needs to sit atop today's data access and data management value pyramid. The characteristics of this DBMS must include the following:
- Every item of data (Datum/Entity/Object/Resource) has Identity
- Identity is achieved via Identifiers that aren't locked at the DBMS, OS, Network, or Application levels
- Object Identifiers and Object values are independent (extricably linked by association)
- Object values should be de-referencable via Object Identifier
- Representation of de-referenced value graph (entity, attributes, and values mesh) must be negotiable (i.e. content negotiation)
- Structured query language must provide mechanism for Creation, Deletion, Updates, and Querying of data objects
- Performance & Scalability across "Closed World" (enterprise) and "Open World" (Internet & Web) realms.
Quick recap, I am not saying that RDBMS engine technology is dead or obsolete. I am simply stating that the era of RDBMS primacy within the data access and data management value pyramid is over.
The problem domain (conceptual model views over heterogeneous data sources) at the apex of the aforementioned pyramid has simply evolved beyond the natural capabilities of the RDBMS which is rooted in "Closed World" assumptions re., data definition, access, and management. The need to maintain domain based conceptual interaction with data is now palpable at every echelon within our "Global Village" - Internet, Web, Enterprise, Government etc.
It is my personal view that an EAV/CR model based DBMS, with support for the seven items enumerated above, can trigger the long anticipated RDBMS downgrade. Such a DBMS would be inherently multi-model because you would need to the best of RDBMS and EAV/CR model engines in a single product, with in-built support for HTTP and other Internet protocols in order to effectively address data representation and serialization issues.
EAV/CR Oriented Data Access & Management Technology
Examples of contemporary EAV/CR frameworks that provide concrete conceptual layers for data access and data management currently include:
- Resource Description Framework (RDF) - an EAV/CR based framework
- RDF Linked Data - EAV/CR based framework that mandates de-referencable HTTP based Identifiers
- ADO.NET Entity Frameworks - Microsoft .NET based EAV/CR framework
- Core Data Services - Mac OS X based EAV/CR framework that evolved from NeXT's Enterprise Object Frameworks (EOF).
The frameworks above provide the basis for a revised AVF pyramid, as depicted below, that reflects today's data access and management realities i.e., an Internet & Web driven global village comprised of interlinked distributed data objects, compatible with "Open World" assumptions.
Related
- The Semantic Way - Alan Cho's Summary of PwC 2009 tech forecast report on the Semantic Web
- Is the RDBMS Doomed - ReadWriteWeb Article
- Anti-RDBMS: a list of Distributed Key-Value Stores - by Richard Jones (CTO Last.FM)
- How & Why Glue is Using Amazon SimpleDB
- Object Database Manifesto (Identity excerpt)
- Database Models Overview
- Ted Nelson Explaining Irregularity and Idiosyncrasy of Data Structures - ZigZag Demo