Open Data Access and Web 2.0 have a very strange relationship that continues to blur the lines of demarcation between where Web 2.0 ends and where Web.Next (i.e Web 3.0, Semantic/Data Web, Web of Databases etc.) starts. But before I proceed, let me attempt to define Web 2.0 one more time: A phase in the evolution web usage patterns that emphasizes Web Services based interaction between âWeb Usersâ and âPoints of Web Presenceâ over traditional âWeb Usersâ and âWeb Sitesâ based interaction. Basically, a transition from visual site interaction to presence based interaction.
BTW - Dare Obasanjo also commented about Web usage patterns in his post titled: The Two Webs. Where he concluded that we had a dichotomy along the lines of: HTTP-for-APIs (2.0) and HTTP-for-Browsers (1.0). Which Jon Udell evolved into: HTTP-Services-Web and HTTP-Intereactive-Web during our recent podcast conversation.
With definitions in place, I will resume my quest to unveil the aforementioned Web 2.0 Data Access Conundrum:
- Emphasis on XML's prowess in the realms of Data and Protocol Modeling alongside Data Representation. Especially as SOAP or REST styles of Web Services and various XML formats (RSS 0.92/1.0/1.1/2.0, Atom, OPML, OCS etc.) collectively define the Web 2.0 infrastructure landscape
- Where a modicum of Data Access appreciation and comprehension does exist it is inherently compromised by business models that mandate some form of âWalled Gardensâ and âData Silosâ
- Mash-ups are a response to said âWalled Gardensâ and âData Silosâ . Mash-ups by definition imply combining things that were not built for recombination.
As you can see from the above, Open Data access isn't genuinely compatible with Web 2.0.
We can also look at the same issue by way of the popular M-V-C (Model View Controller) pattern. Web 2.0 is all about the âVâ and âCâ with a modicum of âMâ at best (data access, open data access, and flexible open data access are completely separate things). The âCâ items represent application logic exposed by SOAP or REST style web services etc. I'll return to this later in this post.
What about Social Networking you must be thinking? Isn't this a Web 2.0 manifestation? Not at all (IMHO). The Web was developed / invented by Tim Berners-Lee to leverage the âNetwork Effectsâ potential of the Internet for connecting People and Data. Social Networking on the other hand, is simply one of several ways by which construct network connections. I am sure we all accept the fact that connections are built for many other reasons beyond social interaction. That said, we also know that through social interactions we actually develop some of our most valuable relationships (we are social creatures after-all).
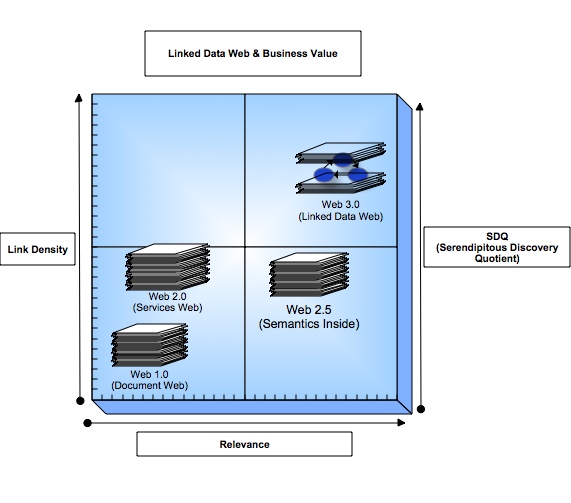
The Web 2.0 Open Data Access impedance reality is ultimately going to be the greatest piece of tutorial and usecase material for the Semantic Web. I take this position because it is human nature to seek Freedom (in unadulterated form) which implies the following:
- Access Data from a myriad of data sources (irrespective of structural differences at the database level)
- Mesh (not Mash) data in new and interesting ways
- Share the meshed data with as many relevant people as possible for social, professional, political, religious, and other reasons
- Construct valuable networks based on data oriented connections
Web 2.0 by definition and use case scenarios is inherently incompatible with the above due to the lack of Flexible and Open Data Access.
If we take the definition of Web 2.0 (above) and rework it with an appreciation Flexible and Open Data Access you would arrive at something like this:
A phase in the evolution of the web that emphasizes interaction between âWeb Usersâ and âWeb Dataâ facilitated by Web Services based APIs and an Open & Flexible Data Access Model â.
In more succinct form:
A pervasive network of people connected by data or data connected by people.
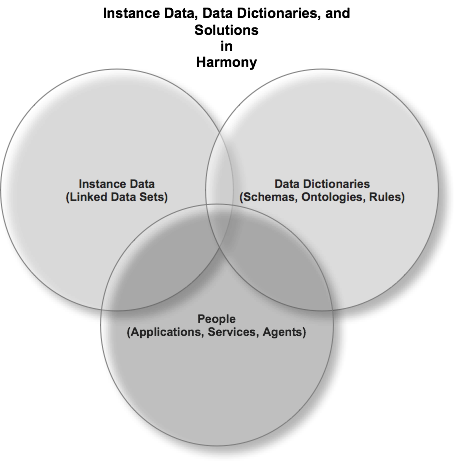
Returning to M-V-C and looking at the definition above, you now have a complete of âMâ which is enigmatic in Web 2.0 and the essence of the Semantic Web (Data and Context).
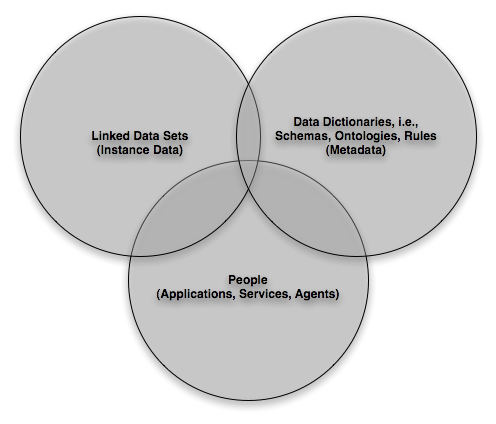
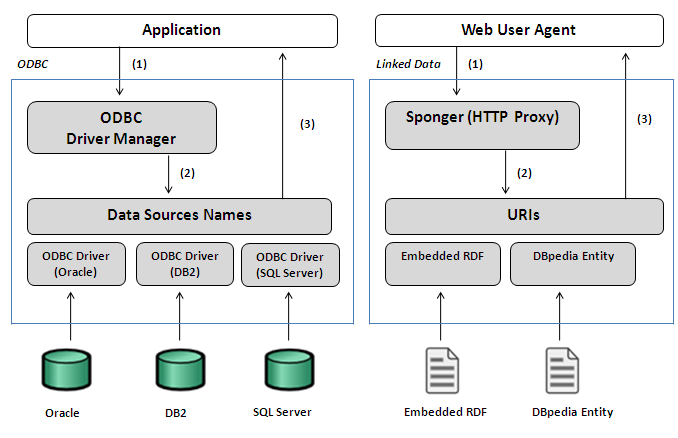
To make all of this possible a palatable Data Model is required. The model of choice is the Graph based RDF Data Model - not to be mistaken for the RDF/XML serialization which is just that, a data serialization that conforms to the aforementioned RDF data model.
The Enterprise Challenge
Web 2.0 cannot and will not make valuable inroads into the the enterprise because enterprises live and die by their ability to exploit data. Weblogs, Wikis, Shared Bookmarking Systems, and other Web 2.0 distributed collaborative applications profiles are only valuable if the data is available to the enterprise for meshing (not mashing).
A good example of how enterprises will exploit data by leveraging networks of people and data (social networks in this case) is shown in this nice presentation by Accenture's Institute for High Performance Business titled: Visualizing Organizational Change.
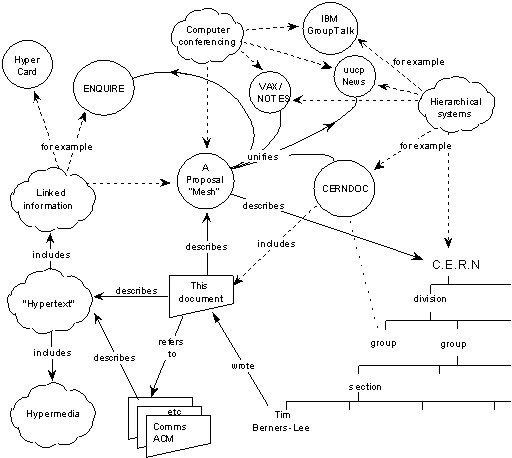
Web 2.0 commentators (for the most part) continue to ponder the use of Web 2.0 within the enterprise while forgetting the congruency between enterprise agility and exploitation of people & data networks (The very issue emphasized in this original Web vision document by Tim Berners-Lee). Even worse, they remain challenged or spooked by the Semantic Web vision because they do not understand that Web 2.0 is fundamentally a Semantic Web precursor due to Open Data Access challenges. Web 2.0 is one of the greatest demonstrations of why we need the Semantic Web at the current time.
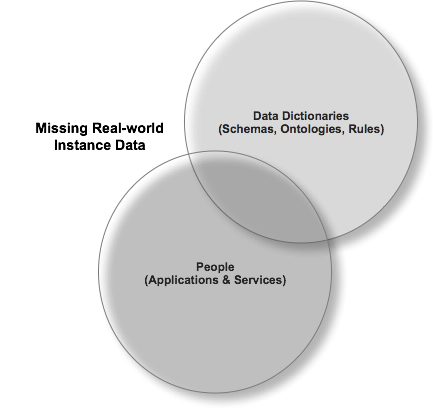
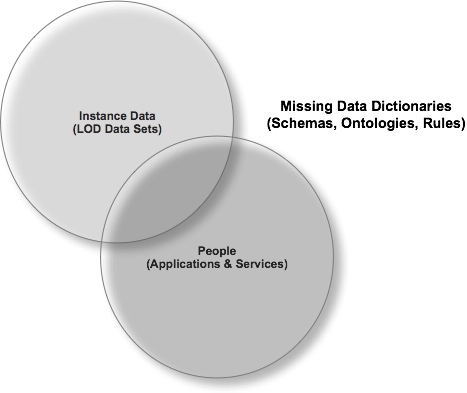
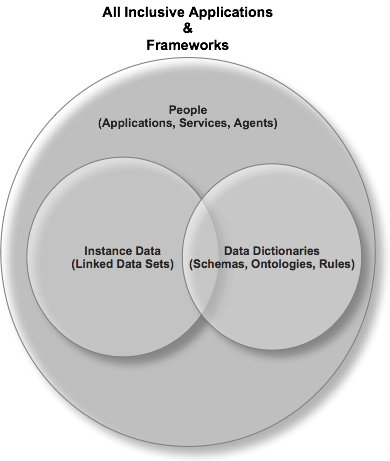
Finally, juxtapose the items below and you may even get a clearer view of what I am an attempting to convey about the virtues of Open Data Access and the inflective role it plays as we move beyond Web 2.0:
Information Management Proposal - Tim Berners-Lee
Visualizing Organizational Change - Accenture Institute of High Performance Business
]]>

 ]]>
]]>
{kind=link}